Article Text

Abstract
Objective Given the complexities of testing the translational capability of new artificial intelligence (AI) tools, we aimed to map the pathways of training/validation/testing in development process and external validation of AI tools evaluated in dedicated randomised controlled trials (AI-RCTs).
Methods We searched for peer-reviewed protocols and completed AI-RCTs evaluating the clinical effectiveness of AI tools and identified development and validation studies of AI tools. We collected detailed information, and evaluated patterns of development and external validation of AI tools.
Results We found 23 AI-RCTs evaluating the clinical impact of 18 unique AI tools (2009–2021). Standard-of-care interventions were used in the control arms in all but one AI-RCT. Investigators did not provide access to the software code of the AI tool in any of the studies. Considering the primary outcome, the results were in favour of the AI intervention in 82% of the completed AI-RCTs (14 out of 17). We identified significant variation in the patterns of development, external validation and clinical evaluation approaches among different AI tools. A published development study was found only for 10 of the 18 AI tools. Median time from the publication of a development study to the respective AI-RCT was 1.4 years (IQR 0.2–2.2).
Conclusions We found significant variation in the patterns of development and validation for AI tools before their evaluation in dedicated AI-RCTs. Published peer-reviewed protocols and completed AI-RCTs were also heterogeneous in design and reporting. Upcoming guidelines providing guidance for the development and clinical translation process aim to improve these aspects.
- artificial intelligence
- decision support systems
- clinical
- data science
- machine learning
- medical informatics
Data availability statement
All data relevant to the study are included in the article or uploaded as online supplemental information. Not applicable.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
- artificial intelligence
- decision support systems
- clinical
- data science
- machine learning
- medical informatics
Summary box
What is already known?
Randomised controlled trials generating the highest grade of evidence are starting to emerge for AI tools in medicine (AI-RCTs).
Even though distinct steps for the development process of clinical diagnostic and prognostic tools are established, there is no specific guidance for AI-based tools and for the conduct of AI-RCTs.
What does this paper add?
A limited number of AI-RCTs have been completed and reported.
AI-RCTs are characterised by heterogenous design and reporting.
There is significant variation in the patterns of development and validation for AI tools before their evaluation in AI-RCTs.
Data that would allow independent replication and implementation of the AI tools are usually not provided in the AI-RCTs.
Introduction
Artificial intelligence (AI) methods are playing an increasingly important role in digital healthcare transformation and precision medicine, particularly because of breakthroughs in diagnostic and prognostic applications developed with deep learning and other complex machine learning approaches. Numerous AI tools have been developed for diverse conditions and settings, demonstrating favourable diagnostic and prognostic performance.1–3 However, similarly to any other clinical intervention,4–6 adoption of AI tools in patient care requires careful evaluation of their external validity and their impact on downstream interventions and clinical outcomes, beyond performance metrics during development and external validation. The most robust evaluation of any diagnostic or therapeutic intervention may be performed in the setting of randomised controlled trials (RCTs), which are now slowly emerging in the AI space.
Even though distinct steps of training, validation and testing for the development of AI tools have been described, there are no standardised recommendations for AI-based diagnostic and predictive modelling in biomedicine.7–10 In addition, overfitting, or the phenomenon of training an AI model that is too closely aligned with a limited training dataset such that it has no generalisation ability, is often of concern in highly parameterised AI models. External validation of AI tools aiming to verify a hyperparameterised model is therefore a critical step in the evaluation process. Furthermore, the extrapolation of model performance from one setting and patient population to others is not guaranteed.11 12 Moreover, concerns have been raised about the transparency of reporting in the AI literature to facilitate independent replication of AI tools.13
Given the complexities of testing the translational capability of new AI tools and the lack of coherent recommendations, we aimed to map the current pathways of training/validation/testing in development process of AI tools in any medical field and identify external validation patterns of AI tools considered for evaluation in dedicated RCTs (here mentioned as AI-RCTs).
Materials and methods
Data source and study selection process
We identified protocols of ongoing AI-RCTs and reports of completed AI-RCTs that evaluated AI tools compared with control strategies in a randomised fashion for any clinical purpose and medical condition. We searched PubMed for publications in peer-review journals in the last 20 years (last search on 31 December 2020) using the following search terms: “artificial intelligence”, “machine learning”, “neural network”, “deep learning”, “cognitive computing”, “computer vision” and “natural language processing”. We did not search for protocols of AI-RCTs published only in protocol registries since the compliance with reporting and the provided information has been shown to be poor compared with peer-reviewed protocols or published reports of clinical trials.14–18 We considered only peer-reviewed reports of protocols of AI-RCTs which provided detailed information on the trial design of our interest. We considered clinical trials in which the AI tool (algorithm) was either previously developed or was planned to be developed (trained) as part of the trial before being evaluated in the RCT. Clinical trial protocols were included irrespectively of their status (ongoing or completed). The listed references of eligible studies were also searched for additional potentially eligible studies. The detailed search algorithm is provided in online supplemental box.
Supplemental material
Mapping of AI tool development: citation content analysis
For each eligible protocol and report of AI-RCT, we scrutinised the cited articles to identify any previous published study reporting on AI tool development (including training, validation or testing) or claiming external validation in an independent population than the one where the AI tool was initial developed. Each potentially eligible study identified above, was subsequently evaluated in full-text to determine whether it describes the development and/or independent evaluation (external validation) of the AI tool of interest. Finally, we searched Google Scholar for articles citing the index development study of the AI tool or its external validation (if any) in order to trace other studies of external validation (onnline supplemental box).
Data collection
A detailed list of information was gathered from each eligible protocol and report of completed AI-RCT using a standardised form which was built and modified, as required, in an iterative process. We extracted relevant information from the main manuscript and any online supplemental material. From each report, we extracted trial and population characteristics which include: single versus multicentre trial, geographical location of the contributing centres, number of arms of randomisation, level of randomisation (patient or clinicians), total sample size, power calculation approach, type of control intervention, underlying medical condition, period of recruitment, funding source (industry related, non-industry related, both, none, none reported), follow-up duration or duration of the intervention, patient-level data collection through dedicated study personnel or from electronic health records, strategies for dealing with missing data; details on the primary outcome(s) of interest which include: single or composite, continuous or binary, outcome adjudication method(s); considering the primary outcome. Among the unique AI tools, we classified the primary outcomes as therapeutic, diagnostic or feasibility outcomes. We documented whether the results of the completed AI-RCT are in favour to intervention based on the AI tool. We extracted information on whether researchers provide access to the code based on which the AI tool was built. We finally assessed the risk of bias (RoB) in the results of completed AI-RCTs that compared the effect of the AI tool compared with other intervention(s) by using the revised Cochrane risk-of-bias tool for randomised trials RoB 2.19
For each study describing the development or external validation of an index AI tool, we extracted the following information: year of publication, recruitment period, geographic area of study population, sample size, clinical field, and whether the authors provided any information that would allow the replication of applied coding. We considered as external validation studies those which fulfilled at least one the following conditions compared with the corresponding development study: different study population, different geographic area, different recruitment period or different group of investigators validating the AI tool.
Statistical analysis
We descriptively analysed the protocols and reports of completed AI-RCTs as a whole and separately. We considered the protocols of already published AI-RCTs as a single report with the index trial. The extracted data were summarised into narrative synthesis and presented in summary tables in the level of AI tools and in the level of AI-RCTs. For illustration purposes, we graphically summarised interconnections of the available development (training/validation/testing) studies, external validation studies and the respective AI-RCTs (either protocols of reports) for each AI tool of interest. We visually evaluated the diversity of the distributions of peer-reviewed development, external validation studies and the ongoing/published reports of AI-RCTs among the unique AI tools. We also illustrated the time lags and differences in sample sizes between different steps of development (whenever applicable) of an AI tool to subsequent evaluation in dedicated AI-RCTs. Illustrations were conducted in R (V.3.4.1; R-Project for Statistical Computing).
Results
Protocols and completed AI-RCTs
The selection process of eligible protocols and reports of AI-RCTs is summarised in online supplemental figure 1. Overall, we identified 23 unique AI-RCTs20–45 (6 protocols and 17 reports of completed AI-RCTs) evaluating the clinical effectiveness of 18 unique AI tools for a variety of conditions (tables 1 and 2, online supplemental file 1). Three of the completed AI-RCTs36 39 45 had previously published protocols.35 38 44 The identified reports were published over a 10-year period (2009–2020). Half of the AI-RCTs were multicentre (52%) and the majority compared the AI-based intervention to a single control intervention (87%). The median target sample size reported in the protocols of AI-RCTs was 298 (IQR 219–850), whereas for the published AI-RCTs was 214 (IQR 100–437) (table 2, online supplemental table 1). Power calculations were available in 18 out of 23 AI-RCTs. The control arms consisted of standard-of-care interventions in all but one study in which a sham intervention was used as control. In one trial, the investigators also considered a historical control group in addition to the two randomised groups in the trial.37 Ten AI-RCTs were funded by non-industry sponsors and seven trials did not specify the financial source. The investigators did not specify any strategies for handling missing data in most AI-RCTs (19 out of 23, 83%). Outcome ascertainment was based on electronic health records in the minority of the AI-RCTs (4 out of 23, 17%), while in the remaining studies either was unclear or conventional adjudication methods were applied. A binary or continuous primary outcome was considered in 7 (30%) and 14 (61%) of the trials. Among the 18 unique AI tools (table 1), 10 tools were examined for therapeutic outcomes, 6 for diagnostic and 2 for feasibility. The results according to the primary outcome favoured the AI intervention in 82% of the completed AI-RCTs (14 out of 17), with 1 trial claiming lower in-hospital mortality rates with the AI intervention25 (table 2, online supplemental table 2). None of the AI-RCTs reported their intention to provide access to the coding of the AI tool. Online supplemental table 3 summarises the detailed risk-of-bias judgement for each domain and the overall judgement for each AI-RCT. Three trials were at low RoB, five trials were judged to raise ‘some concerns’ and nine to be at ‘high RoB’, mainly due to the lack of appropriate/complete reporting related to adherence of intended interventions and in measurement of the outcome of interest.
Descriptive summary of 18 artificial intelligence tools evaluated in AI-RCTs
Characteristics of peer-reviewed protocols and completed RCTs evaluating artificial intelligence tools
Development, external validation and clinical evaluation pathways of AI tools
We identified considerable dissimilarities in the patterns of development, external validation and clinical evaluation steps among AI tools (figures 1 and 2, online supplemental table 4). A peer-reviewed publication describing the development process was not found for 8 out of the 18 unique AI tools. In 12 AI-RCTs, the study population originated from the same geographic area and population as the one where the AI tool was developed in. We were able to identify at least one external validation study linked to a trial only in 11 out of the 23 ongoing/completed AI-RCTs. All of the external validation studies considered a different recruitment period compared with that in the development study, but from the same geographical area in all 11 cases. The number of external validation studies ranged from 1 to 4 per AI tool (figure 1). Three AI tools were evaluated in two different AI-RCTs, and one AI tool was evaluated in three different AI-RCTs with differences in patient populations and examined outcomes (table 1 and figure 1). Among the AI tools with external validation studies, in 6 cases the external validation studies were published at the same time or clearly after the corresponding AI-RCT (figure 2). In those six cases, the external validation studies applied the AI tool in different populations and/or clinical settings, compared with those where it was developed and those studied in the AI-RCT.

Patterns of pathways of development (training, validation and/or testing), external validation and clinical evaluation of artificial intelligence tools in ongoing and completed clinical trials (n=23). In network level, each circle corresponds to an individual study (green, blue, and red for development, external validation and AI-RCTs, respectively). The number below each network represents the number of unique AI tools having identified with the respective pattern (network) of studies. For example, the first network of the top row corresponds to a unique AI tool for which a development study (green circle), four external validation studies (blue circles), and two AI-RCTs (red circles) were found. AI-RCTs, artificial intelligence randomised controlled trials.

Timelines of publications and sample sizes of development (training, validation and/or testing), external validation studies and completed AI-RCTs (n=17). Each circle corresponds to a unique study (development (training, validation, testing) studies in green, external validation studies in blue, and AI-RCTs in red). Due to the wide range of studies’ sample sizes, the values are displaying in logarithmic (log10) scale. AI-RCTs, artificial intelligence randomised controlled trials.
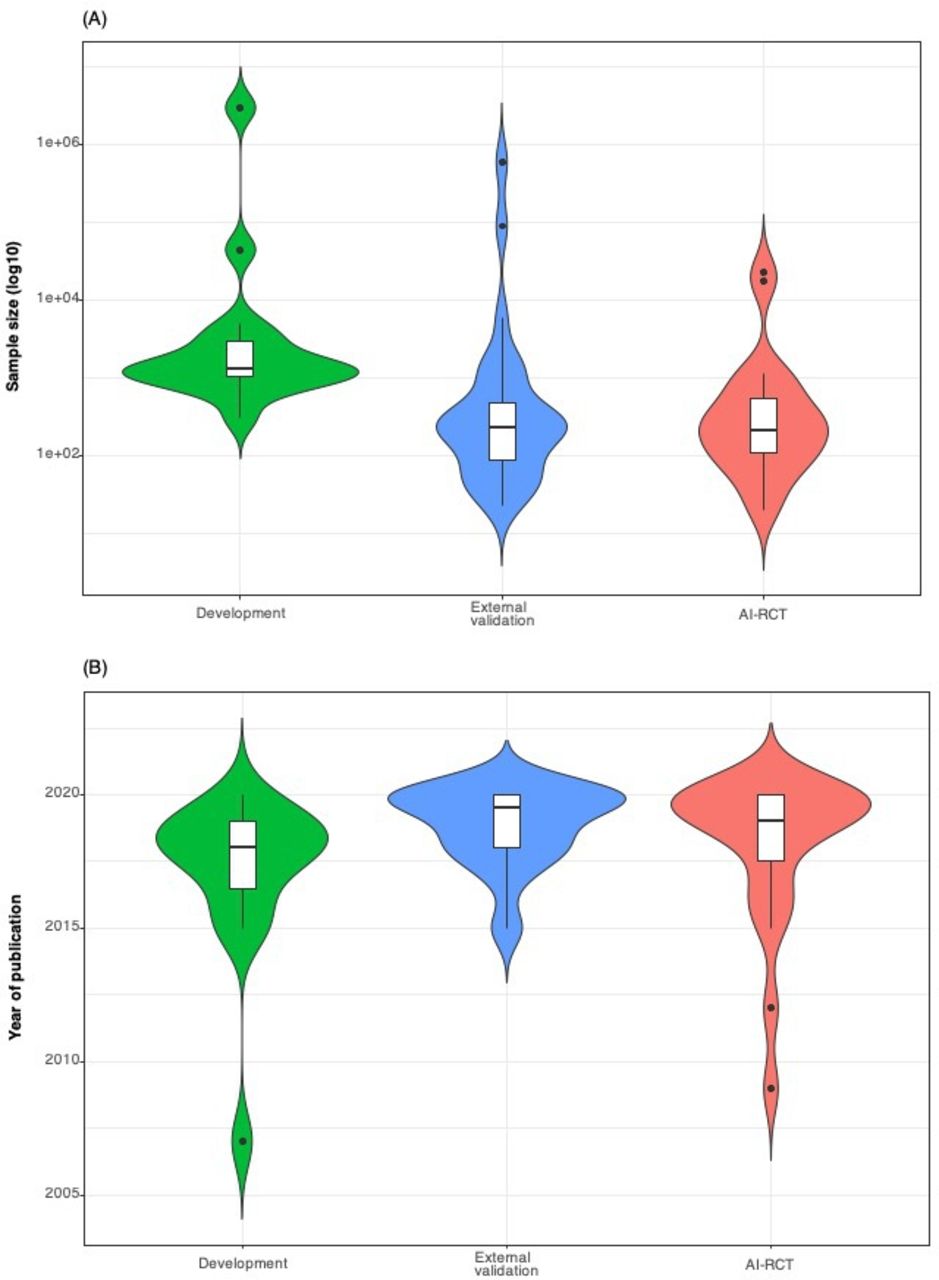
Among the 17 completed AI-RCTs, the distribution of the sample sizes and timelines of publications for development, external validation and AI-RCT reports is shown in figures 2 and 3. The sample sizes of the development studies were larger than the respective external validation studies and AI-RCTs, whereas external validation studies and AI-RCTs did not differ in sample sizes. Median time from publication of a development study to publication of the respective AI-RCT was 1.4 years (IQR 0.2–2.2). The time lag between publication of the development studies to the publication of AI-RCTs varied for different AI tools, but there was considerable overlap of the timelines of external validation and AI-RCT publications (table 1, figure 2, online supplemental tables 1 and 4).
{kind=link}
{kind=link}
{kind=link}
Violin plots showing in comparison the distributions of sample sizes (A) and years of publication (B) of development (training, validation and/or testing), external validation studies and completed AI-RCTs (n=17). AI-RCT, artificial intelligence randomised controlled trials.
Discussion
Large scale real-world data collected from electronic-health records have allowed the development of diagnostic and prognostic tools based on machine learning approaches.46–52 Evaluations of the clinical impact of such tools in dedicated RCTs are now starting to emerge in the literature. Our empirical assessment of the literature identified significant variation in the patterns of AI tool development (training, validation, testing) and external (independent) validation leading up to their evaluation in dedicated AI-RCTs. In this early phase of novel AI-RCTs, trials are characterised by heterogeneous design and reporting. Data that would allow independent replication and implementation of AI tools were not available in any of the AI-RCTs.
There is growing recognition that AI tools need to be held to the same rigorous standard of evidence as other diagnostic and therapeutic tools in medicine with standardised reporting.53–55 The recently published extensions of the COSNORT and Standard Protocol Items: Recommendations for Interventional Trials (SPIRIT) statements for RCTs of AI-based interventions (namely Consolidated Standards of Reporting Trials (CONSORT)-AI56 and SPIRIT-AI)57 are beginning to provide such a framework. Among the items mandated by these documents, investigators in AI-RCT have to provide better clarity around the intended use of the AI intervention, descriptions how the AI intervention can be integrated into the trial setting, and the setting expectations that investigators make the AI intervention and/or its code assessable. Although most of the studies included in the current review were published before these guidelines, the marked heterogeneity in current reporting underscore the urgency of this call and provide a standard for the ongoing evaluation of these kinds of studies.
RCTs remain the cornerstone of evaluation of diagnostic or therapeutic interventions proposed for clinical use, and this should be no less true for AI interventions. While the experience with the clinical application of AI tools is still early, the evaluation standards of these tools should follow well established norms. AI has demonstrated great promise in transforming many aspects of patient care and healthcare delivery, but the rigorous evaluation standards has lagged for AI tools. Despite numerous published AI applications in medicine,1–3 in this empirical assessment we have found that a very small fraction has so far undergone evaluation in dedicated clinical trials. We identified significant variation of model development processes leading up to the AI-RCTs. After initial development of an AI tool, at least one external validation study for that particular tool was found for only 11 out of the 23 AI-RCTs. Furthermore, the AI-RCTs were almost always conducted in the same geographic areas as their respective development studies. Thus, the AI-RCTs in this empirical assessment often failed to provide sufficient information regarding the generalisability and external validity of the AI tools. When considering the application of AI tools in the real world, a ‘table of ingredients’ accompanying the AI tool could be of value. Such a label would include information on how the tool was developed and whether it has been externally validated, including the specific populations, demographic profiles, racial mix, inpatient versus outpatient settings, and other key details. This would allow a potential user to determine whether the AI tool is applicable to their patient or population of interest and whether any deviations in diagnostic or prognostic performance are to be expected.
Along these lines, as with any type of RCT, the choice of primary outcomes in AI-RCTs is also important to consider. Improvement in therapeutic efficacy outcomes with direct patient relevance may be the ultimate criterion of value of an AI tool, but these may also be the most difficult to demonstrate improvements for. The number of studies in each of the three outcome classes in our study (therapeutic, diagnostic, feasibility) was too small to reach conclusions about differences in the probability of statistically significant results between classes. It should also be noted that for diagnostic AI tools, diagnostic performance outcomes that align with the scope of the intervention would be appropriate. However, interpretation of such findings should account for likely dilution of any effect when translating differences in diagnostic outcomes to downstream clinical outcomes.58 Ultimately, investigation of patient-centric outcomes, should remain a priority whenever possible.
The optimal process for the clinical evaluation of AI tools, ranging from model development to AI-RCTs to real-world implementation, is not yet well defined. Dedicated guidelines on the development, reporting and bridging the development-to-implementation gap of AI tools for prognosis or diagnosis, namely Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis-AI (TRIPOD-AI),59 Prediction model Risk Of Bias ASsessment Tool-AI (PROBAST-AI),59 Developmental and Exploratory Clinical Investigation of Decision-AI (DECIDE-AI),60 Standards for Reporting of Diagnostic Accuracy Studies-AI (STARD-AI),61 Quality Assessment of Diagnostic Accuracy Studies-AI (QUADAS-AI),62 will be available soon. The heterogeneity in development, validation and reporting in the existing AI literature that we found in this study might be largely attributable to the lack of consensus on research practices and reporting standards in this space. The translational process from development to clinical evaluation of AI tools is in the early phase of a broader scrutiny of AI in various medical disciplines. The upcoming guideline documents are likely to enhance the reliability, replicability, validity and generalisability of this literature.
Furthermore, it is unknown whether all AI tools necessitate testing in traditional, large-scale AI-RCTs.63 Well-powered, large RCTs that are likely to provide conclusive results are costly, resource intensive and take a long time to complete. Therefore, a clinical evaluation model that routinely requires RCTs may not represent a realistic expectation for the majority of AI tools. However, the ongoing digital transformation in healthcare allows researchers to simplify time-consuming and costly steps of traditional RCTs and to improve efficiency. For example, patient recruitment, follow-up and outcome ascertainment may be performed via nationwide linkage to centralised electronic health records. Natural language processing tools may allow automated screening for patient eligibility and collection of information of patient characteristics and outcomes. Existing web-based, patient-facing portals that are the norm for most healthcare institutions may allow a fully virtual consent process for recruitment. for outcomes’ ascertainment. The extensions of the COSNORT and SPIRIT statements for RCTs of AI-based interventions (namely CONSORT-AI56 and SPIRIT-AI)57 underscore these concepts for facilitating a novel model of AI-RCT.
Limitations
Our empirical evaluation has limitations. First, a number of potentially eligible ongoing trials have not been included, since we summarised peer-reviewed protocols and final reports of AI-RCTs published in PubMed, whereas trials registered in online registries were not considered. However, as has been previously shown,14–18 64 registered protocols often suffer from incomplete reporting, lack of compliance with the conditions for registration and out-of-date information, which would not have allowed us to appropriately characterise the AI tools and their respective development pathways. Second, as part of this evaluation we did not consider a control group of trials (ie, trials evaluating the clinical impact of traditional diagnostic or prognostic tools). However, such trials could not be directly comparable to the AI-RCTs due to fundamental differences in studied interventions and populations. Third, we were not able to comparatively assess the discriminatory performance of the AI tools across the distinct steps of training/validation/testing and external validation, since such performance metrics were neither systematically nor uniformly reported.
Conclusion
In conclusion, we have found that evaluation of AI tools in dedicated RCTs is still infrequent. There is significant variation in patterns of development and validation for AI tools before their evaluation in RCTs. Published peer-reviewed protocols and completed AI-RCTs also varied in design and reporting. Most AI-RCTs do not test the AI tools in geographical areas outside of those where the tools were developed, therefore generalisability remains largely unaddressed. As AI applications are increasingly reported throughout medicine, there is a clear need for structured evaluation of their impact on patients with a focus on effectiveness and safety outcomes, but also costs and patient-centred care, before their large-scale deployment.65 The upcoming guidelines for AI tools aim to guide researchers and fill the translational gaps in the conduct and reporting of development and translation steps. All steps in the translation pathway of these tools should serve the development of meaningful and impactful AI tools without compromise under the pressure of innovation.
Data availability statement
All data relevant to the study are included in the article or uploaded as online supplemental information. Not applicable.
Ethics statements
Patient consent for publication
Ethics approval
Not required.
Acknowledgments
None.
References
Supplementary materials
Supplementary Data
This web only file has been produced by the BMJ Publishing Group from an electronic file supplied by the author(s) and has not been edited for content.
Footnotes
Contributors All authors reviewed the final manuscript for submission and contributed to the study as follows: GCMS contributed to the study design, data extraction and management, interpretation and writing of manuscript. GCMS is the guarantor and responsible for the overall content. GCMS accepts full responsibility for the work and the conduct of the study, had access to the data, and controlled the decision to publish. RS contributed to data extraction and management. PAN contributed to interpretation and writing of manuscript. PAF contributed to interpretation and writing of manuscript. KCS contributed to study design, interpretation and writing of manuscript. CJP contributed to interpretation and writing of manuscript.
Funding The authors have not declared a specific grant for this research from any funding agency in the public, commercial or not-for-profit sectors.
Competing interests None declared.
Patient and public involvement statement Not applicable.
Provenance and peer review Not commissioned; externally peer reviewed.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.