
Abstract
Trait-based approaches advance ecological and evolutionary research because traits provide a strong link to an organism’s function and fitness. Trait-based research might lead to a deeper understanding of the functions of, and services provided by, ecosystems, thereby improving management, which is vital in the current era of rapid environmental change. Coral reef scientists have long collected trait data for corals; however, these are difficult to access and often under-utilized in addressing large-scale questions. We present the Coral Trait Database initiative that aims to bring together physiological, morphological, ecological, phylogenetic and biogeographic trait information into a single repository. The database houses species- and individual-level data from published field and experimental studies alongside contextual data that provide important framing for analyses. In this data descriptor, we release data for 56 traits for 1547 species, and present a collaborative platform on which other trait data are being actively federated. Our overall goal is for the Coral Trait Database to become an open-source, community-led data clearinghouse that accelerates coral reef research.
Design Type(s) | data integration objective • species comparison design • digital curation • observation design |
Measurement Type(s) | ecological observations |
Technology Type(s) | data item extraction from journal article |
Factor Type(s) | Trait |
Sample Characteristic(s) | Scleractinia • marine coral reef biome |
Machine-accessible metadata file describing the reported data (ISA-Tab format)
Similar content being viewed by others


Background & Summary
Most ecosystems are rich in species that display a wide diversity of characteristics1 (i.e., traits). One way to make meaningful generalizations from this diversity has been to identify physiological, ecological or functional traits of organisms to infer (e.g., using traits as explanatory variables) patterns of demography, distribution and abundance, and more broadly, ecosystem function and evolution2. Moreover, species traits can be used as explanatory variables for the responses of ecosystems to environmental change, as functionally significant traits mediate species’ responses to disturbances3. Recently, research has demonstrated the utility of trait-based approaches for understanding the effects of anthropogenic disturbances4, the provisioning of ecosystem services5, species distributions6–8, species composition9,10, and energetic and ecological trade-offs11,12. In seminal papers, compilations of species trait data with broad taxonomic coverage have revealed, for example, a general axis of variation in plants that describes costs and benefits of key chemical, structural and physiological traits11; and factors influencing the metabolic rates of organisms13. However, such broad-scale insights have been restricted to relatively few taxonomic groups, often due to lack of data, particularly information about the ecological context in which data were collected, when such data do exist.
Trait data for stony corals (Cnidaria: Scleractinia) have been collected for more than 100 years and published in many languages. Sufficient data might well exist already for addressing broad-scale hypotheses regarding the ecology and evolution of corals. Although trait compilations are accumulating4,14–16, and new statistical approaches for analysing such data are emerging7,12, these datasets are typically gathered for specific traits in isolation to address specific questions which can result in duplication of effort by separate research groups (e.g., Darling et al.12 and Pratchett et al.17 both independently compiled growth rate data). Trait data also tend to be gathered rapidly, for instance with means extracted from tables that present a mixture of original data and data collected previously by others (i.e., meta-analyses). Such a rapid assembly of data can result in omission of important contextual information (e.g., local environmental conditions and levels of variation and replication), confusion about the origin of the data, preventing appropriate provenance and credit18, and the accidental duplication of data points in large datasets.
In this data descriptor, we introduce the Coral Trait Database: a curated database of trait information for coral species from the global oceans. The goals of the Coral Trait Database are: (i) to assemble disparate information on coral traits, (ii) to provide unrestricted, open-source access to coral trait data, (iii) to facilitate and encourage the appropriate crediting of original data sources, and (iv) to engage the reef coral research community in the collection and quality control of trait data. We release 56 error-checked, validated and referenced traits, and also provide their context of measurement, together with an online system for transparently and accurately archiving and presenting coral trait data in future research. Our vision is an inclusive and accessible data resource to more rapidly advance the science and management of a sensitive ecosystem at a time of unprecedented environmental change.
Methods
The data are held in the Coral Traits Database (https://coraltraits.org). The database was designed to contain individual-level traits and species-level characteristics and is currently focused on shallow water zooxanthellate (‘reef building’) scleractinian corals. Individual-level traits include any potentially heritable quality of an organism19,20. In the database, individual-level traits are accompanied by contextual characteristics, which give information about the environment or situation in which an individual-level trait was measured (e.g., characteristics of the habitat, seawater or an experiment). These contextual variables are important for understanding variation in individual-level traits (e.g., as predictor variables in analyses). For example, if measurement of colony growth rate was measured at a given depth, the latter datum is included to provide important information for the focal measurement. Some individual-level traits have no or little variation (e.g., mode of larval development), and therefore contextual information is not required. Species-level characteristics do not have contextual information because they are characteristics of species as entities (such as geographical range size and maximum depth observed).
For simplicity, we use the single term ‘trait’ to refer to individual-level (variant and invariant), species-level (emergent) and contextual (environmental or situational) measurements. Moreover, these traits are grouped into ten use-classes based on various sub-disciplines of reef coral research: biomechanical, conservation, ecological, geographical, morphological, phylogenetic, physiological, reproductive, stoichiometric, and contextual.
Observation and measurements
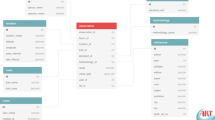
The database contains two core data tables—Observations and Measurements—each of which has a series of associated tables (Fig. 1). We follow the high-level structure of the Observation and Measurement Ontology21 in that observations bind related measurements and potentially provide context for other observations.

(a) The general schema consists of an Observation of a coral colony that is a collection of one or more Measurements associated with the colony. Solid borders represent table associations and dotted borders represent values. Observations have four table associations (contributor, coral species, resource and location) and one value for access (i.e., public or private). Measurements have four table associations (observation, trait, methodology and standard) and five values. (b) An example of an observation where coral growth rate was measured along with two contextual measurements (represented in the database by an eye). All observation-level attributes are required. Required measurement-level attributes are trait, standard, value and value type. Precision details are entered when a value type is not a raw value. Photograph: Emily Darling.
The observation table contains information about the observation of a coral or coral species. Observation-level data must include the Enterer, Species, Location and Resource. Access is an optional variable, and can be controlled by database users entering data for a project that has not yet been published (see https://coraltraits.org/procedures for more information). Observation-level data are the same for all measurements corresponding to the observation. Measurement-level data include the Trait, Value, Standard (measurement unit), Methodology, and estimates of precision (if applicable). The hypothetical example given in Fig. 1b is for growth rate that was measured within the context of a water depth and habitat that were given in the published resource.
The Species table provides taxonomy that is regularly updated by the Taxonomy Advisory Board (https://coraltraits.org/procedures) to keep pace with the rapid rate of revision22–24. The table contains the valid name for each coral species based largely on the World Register of Marine Species (http://www.marinespecies.org), the major clade (Basal, Robust or Complex25), family based on molecular work26, family based on morphology (following Cairns27 or Veron28), and other names and synonyms.
Data acquisition
All public data in the Coral Trait Database and included in this data descriptor release are linked with published resources, which include peer-reviewed papers, taxonomic monographs and books. The original source of entered data must be included (called the primary resource), even when extracted from secondary compilations (e.g., for the purpose of meta-analyses). Secondary sources can be included optionally, and so the database captures both the original data collector and subsequent data compilers, which allows both to be credited when re-using data. Measurement value types, which can be flexibly added to, currently include: raw, mean, median, maximum, minimum, expert opinion (the view of a single expert), group opinion (the consensus of a group of experts), and model derived. Continuous data are typically means extracted from tables or figures unless raw data are available. When available, aggregate values such as means and medians should be accompanied by the number of replicates and a measure of dispersion (e.g., standard deviation). Means and estimates of dispersion from figures in resources were captured using ImageJ29. The data released in this data descriptor have broad taxonomic (Fig. 2), global (Fig. 3) and phylogenetic (Fig. 4) coverage. However, some large data gaps exist, because few species have been comprehensively measured in many locations.

Blue cells correspond with the traits released in this data descriptor. Grey cells correspond with other available data for which thorough error checking is still being conducted.


As for Fig. 2, blue cells indicate traits for species released in this data descriptor and grey cells indicate other available information in the database, still being federated.
Data Records
A static release of the 56 traits contained in this descriptor is available from the Coral Trait Database (Data Citation 1) and Figshare (Data Citation 2). Details and references for the trait data are summarised in Table 1 (available online only). Up-to-date data can be downloaded directly from the database. However, as validation (see Technical Validation, below) and data entry is ongoing, users are recommended to pull data from the static releases, to ensure results remain consistent as the database is updated. Both static releases and datasets downloaded from the database are accompanied by the primary (and, if applicable, secondary) resource lists for the data, which should be credited wherever feasible.
Technical Validation
The database is curated on a voluntary basis, which includes a Managerial Board, Editorial Board, Taxonomy Advisory Board and Database Administrator (https://coraltraits.org/procedures). Database Contributors who add data for a new trait are typically asked to be that trait’s editor. Quality control of data and editorial procedures include:
-
1
Contributor approval: Database users must request permission to become a database contributor, and any observations entered by the contributor are associated with their user account.
-
2
Editorial approval: Once a contributor enters an observation of a coral trait, an email is sent automatically to the editor of that trait. The editor must approve the observation to remove the ‘pending’ flag from the observation record.
-
3
User feedback: Data issues can be reported for any observation using a simple form. Editors are automatically emailed if an issue with one of their traits is reported.
-
4
Duplicate detection: Measurements with the same value, resource, location and species are flagged for confirmation.
-
5
Outlier detection: Frequency histograms are generated in real time when loading trait pages. Outliers can be detected visually (e.g., a very large value for continuous data or a category that has one or few associated measurements for categorical data).
Usage Notes
The data release is a compressed folder containing two files:
-
1
A csv-formatted data file containing all publicly available observation and measurement data, which includes contextual data.
-
2
A csv-formatted resource file containing all the resources (primary and secondary) that correspond with the data. Users are expected to cite the data correctly using these resources.
An example for extracting and reshaping release data for analysis can found online (https://coraltraits.org/procedures).
Additional Information
Table 1 is only available in the online version of this paper.
How to cite this article: Madin, J. S. et al. The Coral Trait Database, a curated database of trait information for coral species from the global oceans. Sci. Data 3:160017 doi: 10.1038/sdata.2016.17 (2016).
References
References
MacArthur, R. H. Geographical Ecology (Harper & Row, 1972).
McGill, B., Enquist, B., Weiher, E. & Westoby, M. Rebuilding community ecology from functional traits. Trends in Ecology and Evolution 21, 178–185 (2006).
Madin, J. S., Baird, A. H., Dornelas, M. & Connolly, S. R. Mechanical vulnerability explains size-dependent mortality of reef corals. Ecology Letters 17, 1008–1015 (2014).
Carpenter, K. E. et al. One-third of reef-building corals face elevated extinction risk from climate change and local impacts. Science 321, 560–563 (2008).
Díaz, S. et al. Incorporating plant functional diversity effects in ecosystem service assessments. Proceedings of the National Academy of Sciences 104, 20684–20689 (2007).
Thuiller, W., Lavorel, S., Midgley, G., Lavergne, S. & Rebelo, T. Relating plant traits and species distributions along bioclimatic gradients for 88 leucadendron taxa. Ecology 85, 1688–1699 (2004).
Keith, S. A., Madin, J. S., Baird, A. H., Hughes, T. P. & Connolly, S. R. Faunal breaks and species composition of Indo-Pacific corals: the role of plate tectonics, environment and habitat distribution. Proceedings of the Royal Society B: Biological Sciences 280, 20130818 (2013).
Sommer, B., Harrison, P. L., Bege, M. & Pandolfi, J. M. Trait-mediated environmental filtering drives assembly at biogeographic transition zones. Ecology 95, 1000–1009 (2014).
Keith, S. A., Newton, A. C., Morecroft, M. D., Bealey, C. E. & Bullock, J. M. Taxonomic homogenization of woodland plant communities over 70 years. Proceedings of the Royal Society B: Biological Sciences 276, 3539–3544 (2009).
Adler, P. B., Fajardo, A. & Kleinhesselink, A. R. Trait‐based tests of coexistence mechanisms. Ecology Letters 16, 1294–1306 (2013).
Wright, I. et al. The worldwide leaf economics spectrum. Nature 428, 821–827 (2004).
Darling, E. S., Alvarez-Filip, L., Oliver, T. A., McClanahan, T. R. & Cote, I. M. Evaluating life-history strategies of reef corals from species traits. Ecology Letters 15, 1378–1386 (2012).
Gillooly, J. F., Brown, J. H., West, G. B., Savage, V. M. & Charnov, E. L. Effects of size and temperature on metabolic rate. Science 293, 2248–2252 (2001).
Baird, A. H., Guest, J. R. & Willis, B. L. Systematic and Biogeographical Patterns in the Reproductive Biology of Scleractinian Corals. Annual Review of Ecology, Evolution and Systematics 40, 551–571 (2009).
Franklin, E. C., Stat, M., Pochon, X., Putnam, H. & Gates, R. GeoSymbio: a hybrid, cloud‐based web application of global geospatial bioinformatics and ecoinformatics for Symbiodinium-host symbioses. Molecular Ecology Resources 12, 369–373 (2012).
Edmunds, P. J. et al. Evaluating the causal basis of ecological success within the scleractinia: an integral projection model approach. Marine Biology 161, 2719–2734 (2014).
Pratchett, M. S. et al. Spatial, temporal and taxonomic variation in coral growth—implications for the structure and function of coral reef ecosystems. Oceanography and Marine Biology: An Annual Review 53, 215–296 (2015).
Costello, M. J., Michener, W. K., Gahegan, M., Zhang, Z.-Q. & Bourne, P. E. Biodiversity data should be published, cited, and peer reviewed. Trends in Ecology and Evolution 28, 454–461 (2013).
Violle, C. et al. Let the concept of trait be functional. Okios 116, 882–892 (2007).
Cadotte, M. W., Cavender-Bares, J., Tilman, D. & Oakley, T. H. Using Phylogenetic, Functional and Trait Diversity to Understand Patterns of Plant Community Productivity. PLoS ONE 4, e5695 (2009).
Madin, J. S., Bowers, S., Schildhauer, M. & Krivov, S. An ontology for describing and synthesizing ecological observation data. Ecological Informatics 2, 279–296 (2007).
Benzoni, F., Stefani, F., Pichon, M. & Galli, P. The name game: morpho-molecular species boundaries in the genus Psammocora (Cnidaria, Scleractinia). Zoological Journal of the Linnean Society 160, 421–456 (2010).
Budd, A. F., Fukami, H., Smoth, N. D. & Knowlton, N. Taxonomic classification of the reef coral family Mussidae (Cnidaria: Anthozoa: Scleractinia). Zoological Journal of the Linnean Society 166, 465–529 (2012).
Huang, D. et al. Towards a phylogenetic classification of reef corals: the Indo-Pacific genera Merulina, Goniastrea and Scapophyllia (Scleractinia, Merulinidae). Zoologica Scripta 43, 531–548 (2014).
Stolarski, J. et al. The ancient evolutionary origins of Scleractinia revealed by azooxanthellate corals. BMC Evolutionary Biology 11, 316 (2011).
Fukami, H. et al. Mitochondrial and Nuclear Genes Suggest that Stony Corals Are Monophyletic but Most Families of Stony Corals Are Not (Order Scleractinia, Class Anthozoa, Phylum Cnidaria). PLoS ONE 3, e3222 (2008).
Cairns, S. D. Species richness of recent scleractinia. Atoll Research Bulletin 459, 1–47 (1999).
Veron, J. E. N. Corals of the World. Australian Institute of Marine Science and CCR Qld Pty Ltd, (2000).
Schneider, C. A., Rasband, W. S. & Eliceiri, K. W. NIH Image to ImageJ: 25 years of image analysis. Nature Methods 9, 671–675 (2012).
Madin, J. S. & Connolly, S. R. Ecological consequences of major hydrodynamic disturbances on coral reefs. Nature 444, 477–480 (2006).
Abe, N. Post-larval development of the coral Fungia actiniformis var. palawensis Doderlein. Palao Tropical Biological Station Studies 1, 73–93 (1937).
Atoda, K. The larva and postlarval development of some reef-building corals. II. Stylophora pistillata (Esper). Sci. Rep. Tohoku. Univ. Ser. 7 4, 48–64 (1947).
Atoda, K. The larva and post-larval development of some reef-building corals V. Seriatopora hystrix (Dana). Scientific Reports of Tohoku University 4th series (Biology) 19, 33–39 (1951).
Atoda, K. The larva and postlarval development of the reef-building corals IV. Galaxea aspera quelch. Journal of Morphology 89, 17–35 (1951).
Atoda, K. The larva and postlarval development of the reef-building corals III. Acropora bruggemanni (BROOK). Journal of Morphology 89, 1–15 (1951).
Gleason, D. F., Danilowicz, B. S. & Nolan, C. J. Reef waters stimulate substratum exploration in planulae from brooding Caribbean corals. Coral Reefs 28, 549–554 (2009).
Harii, S., Kayanne, H., Takigawa, H., Hayashibara, T. & Yamamoto, M. Larval survivorship, competency periods and settlement of two brooding corals, Heliopora coerulea and Pocillopora damicornis. Marine Biology 141, 39–46 (2002).
Harrigan, J. F. The planula larva of Pocillopora damicornis: lunar periodicity of swarming and substratum selection behavior. University of Hawaii, Thesis No 475 (1972).
Hodgson, G. Abundance and distribution of planktonic coral larvae in Kaneohe Bay, Oahu, Hawaii. Marine Ecology Progress Series 26, 61–71 (1985).
Motoda, S. Observation of Period of Extrusion of Planula of Goniastrea aspera (Verrill.). Kagaku Nanyo 1, 5–7 (1939).
Al Rousan, S., Al Moghrabi, S., Pätzold, J. & Wefer, G. Environmental and biological effects on the stable oxygen isotope records of corals in the northern Gulf of Aqaba, Red Sea. Marine Ecology Progress Series 239, 301–310 (2002).
Alvarez, K., Camero, S., Alarcón, M. E., Rivas, A. & González, G. Physical and mechanical properties evaluation of Acropora palmata coralline species for bone substitution applications. Journal of Materials Science: Materials in Medicine 13, 509–515 (2002).
Baker, P. A. & Weber, J. N. Coral growth rate: Variation with depth. Physics of the Earth and Planetary Interiors 10, 135–139 (1975).
Bosscher, H. Computerized tomography and skeletal density of coral skeletons. Coral Reefs 12, 97–103 (1993).
Bucher, D. J., Harriott, V. J. & Roberts, L. G. Skeletal micro-density, porosity and bulk density of acroporid corals. Journal of Experimental Marine Biology and Ecology 228, 117–136 (1998).
Carricart-Ganivet, J. P., Beltran-Torres, A. U., Merino, M. & Ruiz-Zarate, M. A. Skeletal extension, density and calcification rate of the reef building coral Montastraea annularis (Ellis and Solander) in the Mexican Caribbean. Bulletin of Marine Science 66, 215–224 (2000).
Dar, M. A. & Mohammed, T. A. Seasonal variations in the skeletogensis process in some branching corals of the Red Sea. Thalassas 25, 31–44 (2009).
Dodge, R. E. & Brass, G. W. Skeletal extension, density and calcification of the reef coral, Montastrea annularis: St. Croix, U,S. Virgin Islands. Bulletin of Marine Science 34, 288–307 (1984).
Draschba, S., Pätzold, J. & Wefer, G. North Atlantic climate variability since AD 1350 recorded in δ 18 O and skeletal density of Bermuda corals. International Journal of Earth Sciences 88, 733–741 (2000).
Elizalde Rendón, E. M., Horta Puga, G., González Diaz, P. & Carricart Ganivet, J. P. Growth characteristics of the reef-building coral Porites astreoides under different environmental conditions in the Western Atlantic. Coral Reefs 29, 607–614 (2010).
Ghiold, J. & Enos, P. Carbonate production of the coral Diploria labyrinthiformis in south Florida patch reefs. Marine Geology 45, 281–296 (1982).
Gladfeiter, E. H. Skeletal development in Acropora cervicornis: I. Patterns of calcium carbonate accretion in the axial corallite. Coral Reefs 1, 45–51 (1982).
Heiss, G. A. Carbonate production by scleractinian corals at Aqaba, Gulf of Aqaba, Red Sea. Facies 33, 19–34 (1995).
Helmle, K. P. & Dodge, R. E. Sclerochronology. In: Encyclopedia of Modern Coral Reefs (ed. Hopley, D.) 958–966 (Springer, 2011).
Highsmith, R. C. Coral Bioerosion: Damage Relative to Skeletal Density. The American Naturalist 117, 193 (1981).
Highsmith, R. C. Coral growth rates and environmental control of density banding. Journal of Experimental Marine Biology and Ecology 37, 105–125 (1979).
Highsmith, R. C., Lueptow, R. L. & Schonberg, S. C. Growth and bioerosion of three massive corals on the Belize barrier reef. Marine Ecology Progress Series 13, 261–271 (1983).
Hughes, T. P. Skeletal density and growth form of corals. Marine Ecology Progress Series 35, 259–266 (1987).
Liberman, T., Genin, A. & Loya, Y. Effects on growth and reproduction of the coral Stylophora pistillata by the mutualistic damselfish Dascyllus marginatus. Marine Biology 121, 741–746 (1995).
Lough, J. & Barnes, D. Comparisons of skeletal density variations in Porites from the central Great Barrier Reef. Journal of Experimental Marine Biology and Ecology 155, 1–25 (1992).
Lough, J. M. & Barnes, D. J. Intra-annual timing of density band formation of Porites coral from the central Great Barrier Reef. Journal of Experimental Marine Biology and Ecology 135, 35–57 (1990).
Manzello, D. P. Coral growth with thermal stress and ocean acidification: lessons from the eastern tropical Pacific. Coral Reefs 29, 749–758 (2010).
Manzello, D. P., Enochs, I. C., Kolodziej, G. & Carlton, R. Coral growth patterns of Montastraea cavernosa and Porites astreoides in the Florida Keys: The importance of thermal stress and inimical waters. Journal of Experimental Marine Biology and Ecology 471, 198–207 (2015).
Marshall, P. A. Skeletal damage in reef corals:relating resistance to colony morphology. Marine Ecology Progress Series 200, 177–189 (2000).
Meyer, J. L. & Schultz, E. T. Tissue condition and growth rate of corals associated with schooling fish. Limnol. Oceangr. 30, 157–166 (1985).
Mitsuguchi, T., Matsumoto, E. & Uchida, T. Mg/Ca and Sr/Ca ratios of Porites coral skeleton: Evaluation of the effect of skeletal growth rate. Coral Reefs 22, 381–388 (2003).
Morgan, K. M. & Kench, P. S. Skeletal extension and calcification of reef-building corals in the central Indian Ocean. Marine Environmental Research 81, 78–82 (2012).
Oliver, J., Chalker, B. & Dunlap, W. Bathymetric adaptations of reef-building corals at davies reef, great barrier reef, Australia. I. Long-term growth responses of Acropora formosa (Dana 1846). Journal of Experimental Marine Biology and Ecology 73, 11–35 (1983).
Risk, M. J. & Sammarco, P. W. Cross-shelf trends in skeletal density of the massive coral Pontes lobata from the Great Barrier Reef. Marine Ecology Progress Series 69, 195–200 (1991).
Scoffin, T. P., Tudhope, A. W., Brown, B. E., Chansang, H. & Cheeney, R. F. Patterns and possible environmental controls of skeletogenesis of Porites lutea, South Thailand. Coral Reefs 11, 1–11 (1992).
Smith, L. W., Barshis, D. & Birkeland, C. Phenotypic plasticity for skeletal growth, density and calcification of Porites lobata in response to habitat type. Coral Reefs 26, 559–567 (2007).
Tanzil, J. T. I., Brown, B. E., Tudhope, A. W. & Dunne, R. P. Decline in skeletal growth of the coral Porites lutea from the Andaman Sea, South Thailand between 1984 and 2005. Coral Reefs 28, 519–528 (2009).
Torres, J. L., Armstrong, R. A., Corredor, J. E. & Gilbes, F. Physiological Responses of Acropora cervicornis to Increased Solar Irradiance†. Photochemistry and Photobiology 83, 839–850 (2007).
Wellington, G. M. & Glynn, P. W. Environmental influences on skeletal banding in eastern Pacific (Panama) corals. Coral Reefs 1, 215–222 (1983).
Cairns, S. D. The deep water scleractinia of the Caribbean Sea and adjacent waters. Studies on the fauna of Curacau and other Caribbean Islands 57, 1–341 (1979).
Lin, M. F., Kitahara, M. V., Tachikawa, H., Keshavmurthy, S. & Chen, C. A. A New Shallow-Water Species, Polycyathus chaishanensis sp. nov. (Scleractinia: Caryophylliidae), from Chaishan, Kaohsiung, Taiwan. Zoological Studies 51, 213–221 (2012).
Wallace, C. C., Done, B. J. & Muir, P. R. Revision and catalogue of worldwide staghorn corals Acropora and Isopora (Scleractinia: Acroporidae) in the Museum of Tropical Queensland. Memoirs of the Queensland Museum—Nature 57, 1–255 (2012).
Delbeek, J. C. et al. IUCN red list (version 2009.1) http://www.iucnredlist.org/ (2009).
Díaz, M. & Madin, J. Macroecological relationships between coral species’ traits and disease potential. Coral Reefs 30, 73–84 (2010).
Veron, J. E. N. Corals of Australia and the Indo-Pacific. University of Hawaii Press (1986).
Ditlev, H. New Scleractinian corals (Cnidaria: Anthozoa) from Sabah, North Borneo. Description of one new genus and eight new species, with notes on their taxonomy and ecology. Zool. Med. Leiden 7, 193–219 (2003).
Veron, J. E. N. Conservation of biodiversity: a critical time for the hermatypic corals of Japan. Coral Reefs 11, 13–21 (1992).
Veron, J. E. N. & Pichon, M. Scleractinia of Eastern Australia. Part III. Families Agariciidae, Siderastreidae, Fungiidae, Oculinidae, Merulinidae, Mussidae, Pectiniidae, Caryophylliidae, Dendrophylliidae. Australian Institute of Marine Science Monograph Series 4 (ANU Press, 1980).
Wallace, C. Staghorn Corals of the World: A revision of the genus Acropora. CSIRO Publishing, (1999).
Bare, A. Y. et al. Mesophotic communities of the insular shelf at Tutuila, American Samoa. Coral Reefs 29, 369–377 (2010).
Bongaerts, P. et al. Mesophotic coral ecosystems on the walls of Coral Sea atolls. Coral Reefs 30, 335–335 (2011).
Bouchon, C. Quantitative Study of the Scleractinian Coral Communities of a Fringing Reef of Reunion Island (Indian Ocean). Marine Ecology Progress Series 4, 273–288 (1981).
Bridge, T. C. L. et al. Diversity of Scleractinia and Octocorallia in the mesophotic zone of the Great Barrier Reef, Australia. Coral Reefs 31, 179–189 (2011).
Bridge, T. C. L., Hughes, T. P., Guinotte, J. M. & Bongaerts, P. Call to protect all coral reefs. Nature Climate Change 3, 528–530 (2013).
Denis, V., De Palmas, S., Benzoni, F. & Chen, C. A. Extension of the known distribution and depth range of the scleractinian coral Psammocora stellata: first record from a Taiwanese mesophotic reef. Mar. Biodiv. 45, 619–620 (2014).
Dinesen, Z. D. A revision of the coral genus Leptoseris (Scleractinia: Fungiina: Agariciidae). Memoirs of the Queensland Museum 20, 181–235 (1980).
Dinesen, Z., Bongaerts, P., Bridge, T., Kahng, S. & Luck, D. The importance of the coral genus Leptoseris to mesophotic coral communities in the Indo-Pacific. 12th International Coral Reef Symposium, poster (2012).
Eyal, G. et al. Euphyllia paradivisa, a successful mesophotic coral in the northern Gulf of Eilat/Aqaba, Red Sea. Coral Reefs 35, 91–102 (2016).
Eyal, G. et al. Spectral Diversity and Regulation of Coral Fluorescence in a Mesophotic Reef Habitat in the Red Sea. PLoS ONE 10, e0128697 (2015).
Goreau, T. F. & Wells, J. W. The shallow-water Scleractinia of Jamaica: Revised list of species and their vertical distribution range. Bulletin of Marine Science 17, 442–453 (1967).
Kahng, S. E. & Maragos, J. E. The deepest, zooxanthellate scleractinian corals in the world? Coral Reefs 25, 254–254 (2006).
Kühlmann, D. H. H. Composition and ecology of deep-water coral associations. Helgoländer Meeresuntersuchungen 36, 183–204 (1983).
Maragos, J. E. & Jokiel, P. L. Reef corals of Johnston Atoll: one of the world’s most isolated reefs. Coral Reefs 4, 141–150 (1986).
Mass, T. et al. Photoacclimation of Stylophora pistillata to light extremes: metabolism and calcification. Marine Ecology Progress Series 334, 93–102 (2007).
Muir, P. R., Wallace, C. C., Done, T. & Aguirre, J. D. Limited scope for latitudinal extension of reef corals. Science 348, 1135–1138 (2015).
Muir, P., Wallace, C., Bridge, T. C. L. & Bongaerts, P. Diverse Staghorn Coral Fauna on the Mesophotic Reefs of North-East Australia. PLoS ONE 10, e0117933 (2015).
Rooney, J. et al. Mesophotic coral ecosystems in the Hawaiian Archipelago. Coral Reefs 29, 361–367 (2010).
Titlyanov, E. A. & Latypov, Y. Y. Light-dependence in scleractinian distribution in the sublittoral zone of South China Sea Islands. Coral Reefs 10, 133–138 (1991).
Wagner, D. et al. Mesophotic surveys of the flora and fauna at Johnston Atoll, Central Pacific Ocean. Mar. Biodivers. Rec 7, e68 (2014).
Wallace, C. & Dale, M. B. An Information Analysis Approach to Zonation Patterns of the Coral Genus Acropora on Outer Reef Buttresses. Atoll Research Bulletin 220, 95 (1978).
Babcock, R. C. Comparative Demography of Three Species of Scleractinian Corals Using Age- and Size-Dependent Classifications. Ecological Monographs 61, 225 (1991).
Hughes, T. P., Connolly, S. R. & Keith, S. A. Geographic ranges of reef corals (Cnidaria: Anthozoa: Scleractinia) in the Indo-Pacific. Ecology 94, 1659 (2013).
Antonius, A. Occurrence and distribution of stony corals (Anthozoa and Hydrozoa) in the vicinity of Santa Marta, Colombia. Boletín de investigaciones marinas y costeras 6, 89–103 (1972).
Brandt, M. E. The effect of species and colony size on the bleaching response of reef-building corals in the Florida Keys during the 2005 mass bleaching event. Coral Reefs 28, 911–924 (2009).
Bronstein, O. & Loya, Y. Daytime spawning of Porites rus on the coral reefs of Chumbe Island in Zanzibar, Western Indian Ocean (WIO). Coral Reefs 30, 441–441 (2011).
Claereboudt, M. R. Porites decasepta: a new species of scleractinian coral (Scleractinia, Poritidae) from Oman. Zootaxa 1188, 55–62 (2006).
Dustan, P. & Halas, J. C. Changes in the reef-coral community of Carysfort reef, Key Largo, Florida: 1974 to 1982. Coral Reefs 6, 91–106 (1987).
Edmondson, C. H. Growth of Hawaiian corals. Bull. Bernice P. Bishop Museum 58, 1–38 (1929).
Hunter, C. L. Genotypic Diversity and Population Structure of the Hawaiian Reef Coral, Porites Compressa. University of Hawaii, (1988).
López-Pérez, R. A., Reyes-Bonilla, H., Budd, A. F. & Correa-Sandoval, F. The taxonomic status of Porites sverdrupi, an endemic coral of the Gulf of California. Ciencias Marinas 29, 677–691 (2003).
Oren, U., Benayahu, Y., Lubinevsky, H. & Loya, Y. Colony Integration during Regeneration in the Stony Coral Favia favus. Ecology 82, 802 (2001).
Potts, D. C., Done, T. J., Isdale, P. J. & Fisk, D. A. Dominance of a coral community by the genus Porites (Scleractinia). Marine Ecology Progress Series 23, 79–84 (1985).
Richardson, L. L. & Voss, J. D. Changes in a coral population on reefs of the northern Florida Keys following a coral disease epizootic. Marine Ecology Progress Series 297, 147–156 (2005).
Szmant, A. M., Weil, E., Miller, M. W. & Colón, D. E. Hybridization within the species complex of the scleractinan coral Montastraea annularis. Marine Biology 129, 561–572 (1997).
Van Moorsel, G. Reproductive strategies in two closely related stony corals (Agaricia, Scleractinia). Marine Ecology Progress Series 13, 273–283 (1983).
Veron, J. E. N. & Pichon, M. Scleractinia of Eastern Australia. Part III. Families Agariciidae, Siderastreidae, Fungiidae, Oculinidae, Merulinidae, Mussidae, Pectiniidae, Caryophylliidae, Dendrophylliidae. Australian Institute of Marine Science Monograph Series 4 ANU Press (1980).
Veron, J. E. N. & Pichon, M. Scleractinia of Eastern Australia, Part I. Families Thamnasteriidae, Astrocoenidae, Pocilloporidae. Australian Institute of Marine Science Monograph Series 1 (ANU Press, 1976).
Veron, J. E. N. & Pichon, M. Scleractinia of Eastern Australia, Part IV. Family Poritidae. Australian Institute of Marine Science Monograph Series 6 (ANU Press, 1982).
Veron, J. E. N., Pichon, M. & Wijsman-Best, M. Scleractinia of Eastern Australia, Part II. Families Faviidae, Trachyphyliidae Australian Institute of Marine Science Monograph Series 3 (ANU Press, 1977).
Veron, J. E. N. & Wallace, C. C. Scleractinia of Eastern Australia, Part V. Family Acroporidae Australian Institute of Marine Science Monograph Series 6 (ANU Press, 1984).
Voss, J. D. & Richardson, L. L. Coral diseases near Lee Stocking Island, Bahamas: patterns and potential drivers. Diseases of Aquatic Organisms 69, 33–40 (2006).
Wallace, C. C. & Wolstenholme, J. Revision of the coral genus Acropora (Scleractinia: Astrocoeniina: Acroporidae) in Indonesia. Zoological Journal of the Linnean Society 123, 199–384 (1998).
Yamano, H., Sugihara, K. & Nomura, K. Rapid poleward range expansion of tropical reef corals in response to rising sea surface temperatures. Geophys. Res. Lett. 38, n/a–n/a (2011).
Australian Institute of Marine Science AIMS Coral Fact Sheets http://coral.aims.gov.au (2013).
Cairns, S. D. A revision of the ahermatypic Scleractinia of the Galapagos and Cocos Islands. Smithsonian Contributions to Zoology 504, 1–44 (1991).
Pichon, M., Chuang, Y. Y. & Chen, C. A. Pseudosiderastrea formosa sp. nov. (Cnidaria: Anthozoa: Scleractinia) a new coral species endemic to Taiwan. Zoological Studies 51, 93–98 (2012).
Veron, J. E. N. New Scleractinia from Australian coral reefs. Records of the Western Australian Museum 12, 147–183 (1985).
Zapata, F. A., Rodríguez-Ramírez, A., Rodríguez-Moreno, M., Muñoz, C. G. & López-Victoria, M. Confirmation of the occurrence of the coral Pavona chiriquiensis Glynn, Maté and Stemann (Cnidaria: Anthozoa: Agariciidae) in the Colombian Pacific. Boletín de Investigaciones Marinas y Costeras 36, 307–312 (2007).
Acosta, A. & Zea, S. Sexual reproduction of the reef coral Montastreacavernosa (Scleractinia: Faviidae) in the Santa Marta area, Caribbean coast of Colombia. Marine Biology 128, 141–148 (1997).
Anthony, K. R. Coral suspension feeding on fine particulate matter. Journal of Experimental Marine Biology and Ecology 232, 85–106 (1999).
Berkelmans, R. & Willis, B. L. Seasonal and local spatial patterns in the upper thermal limits of corals on the inshore Central Great Barrier Reef. Coral Reefs 18, 219–228 (1999).
Burns, J. H. R., Rozet, N. K. & Takabayashi, M. Morphology, severity, and distribution of growth anomalies in the coral, Montipora capitata, at Wai‘ōpae, Hawai‘i. Coral Reefs 30, 819–826 (2011).
Edmunds, P. J. & Davies, P. S. An energy budget for Porites porites (Scleractinia). Marine Biology 92, 339–347 (1986).
Edmunds, P. J. & Davies, P. S. An energy budget for Porites porites (Scleractinia), growing in a stressed environment. Coral Reefs 8, 37–43 (1989).
Hall, V. R. & Hughes, T. P. Reproductive Strategies of Modular Organisms: Comparative Studies of Reef- Building Corals. Ecology 77, 950 (1996).
Harriott, V. J. Reproductive ecology of four scleratinian species at Lizard Island, Great Barrier Reef. Coral Reefs 2, 9–18 (1983).
Lasker, H. R. Phenotypic Variation in the Coral Montastrea cavernosa and Its Effects on Colony Energetics. Biological Bulletin 160, 292 (1981).
Palardy, J. E., Grottoli, A. G. & Matthews, K. A. Effect of naturally changing zooplankton concentrations on feeding rates of two coral species in the Eastern Pacific. Journal of Experimental Marine Biology and Ecology 331, 99–107 (2006).
Patterson, M. R., Sebens, K. P. & Olson, R. R. In situ measurements of flow effects on primary production and dark respiration in reef corals. Limnol. Oceangr. 36, 936–948 (1991).
Sier, C. J. S. & Olive, P. J. W. Reproduction and reproductive variability in the coral Pocillopora verrucosa from the Republic of Maldives. Marine Biology 118, 713–722 (1994).
Szmant, A. M. Reproductive ecology of Caribbean reef corals. Coral Reefs 5, 43–53 (1986).
Tricas, T. C. Prey selection by coral-feeding butterflyfishes: strategies to maximize the profit. Environ Biol Fish 25, 171–185 (1989).
Alroy, J. et al. Effects of sampling standardization on estimates of Phanerozoic marine diversification. Proceedings of the National Academy of Sciences 98, 6261–6266 (2001).
Sepkoski, J. J. A compendium of fossil marine animal genera. Bulletins of American Paleontology 363, 1–560 (2002).
Wells, J. W. Treatise on Invertebrate Palaeontology, Part F. University of Kansas Press (1968).
Huang, D. & Roy, K. The future of evolutionary diversity in reef corals. Philosophical Transactions of the Royal Society B: Biological Sciences 370, 20140010–20140010 (2015).
Anthony, K. R. & Fabricius, K. E. Shifting roles of heterotrophy and autotrophy in coral energetics under varying turbidity. Journal of Experimental Marine Biology and Ecology 252, 221–253 (2000).
Carricart Ganivet, J. P., Cabanillas Terán, N., Cruz Ortega, I. & Blanchon, P. Sensitivity of Calcification to Thermal Stress Varies among Genera of Massive Reef-Building Corals. PLoS ONE 7, e32859 (2012).
Chauvin, A., Denis, V. & Cuet, P. Is the response of coral calcification to seawater acidification related to nutrient loading? Coral Reefs 30, 911–923 (2011).
Clausen, C. D. & Roth, A. A. Effect of temperature and temperature adaptation on calcification rate in the hermatypic coral Pocillopora damicornis. Marine Biology 33, 93–100 (1975).
Cox, W. W. The relation of temperature to calcificatonin Montipora verrucosa, M.A. Thesis, Loma Linda University, (1971).
Davies, P. S. The role of zooxanthellae in the nutritional energy requirements of Pocillopora eyedouxi. Coral Reefs 2, 181–186 (1984).
Edmunds, P. J. The effect of sub-lethal increases in temperature on the growth and population trajectories of three scleractinian corals on the southern Great Barrier Reef. Oecologia 146, 350–364 (2005).
Edmunds, P. J., Brown, D. & Moriarty, V. Interactive effects of ocean acidification and temperature on two scleractinian corals from Moorea, French Polynesia. Glob. Change Biol. 18, 2173–2183 (2012).
Herfort, L., Thake, B. & Taubner, I. Bicarbonate stimulation of calcification and photosynthesis in two hermatypic corals. Journal of Phycology 44, 91–98 (2008).
Horst, G. P. Effects of temperature and CO2 variation on calcification and photosynthesis of two branching reef corals. Unpublished MS thesis, California State University, Northridge (2004).
Hossain, M. M. M. & Ohde, S. Calcification of cultured Porites and Fungia under different aragonite saturation states of seawater. Proceedings of the 10th International Coral Reef Symposium 597–606 (2006).
Marubini, F., Barnett, H., Langdon, C. & Atkinson, M. J. Dependence of calcification on light and carbonate ion concentration for the hermatypic coral Porites compressa. Marine Ecology Progress Series 220, 153–162 (2001).
Marubini, F. & Davies, P. S. Nitrate increases zooxanthellae population density and reduces skeletogenesis in corals. Mar. Biol. 127, 319–328 (1996).
Marubini, F. & Thake, B. Bicarbonate addition promotes coral growth. Limnol. Oceangr. 44, 716–720 (1999).
Muehllehner, N. Growth and morphology in Acropora under increasing carbon dioxide and the effect of increased temperature and carbon dioxide on the photosynthesis and growth of Porites rus and Pocillopora meandrina. Thesis California State University, Northridge 98 (2008).
Ohde, S. & Mozaffar Hossain, M. M. Effect of CaCO3 (aragonite) saturation state of seawater on calcification of Porites coral. Geochem. J. 38, 613–621 (2004).
Schneider, K. & Erez, J. The effect of carbonate chemistry on calcification and photosynthesis in the hermatypic coral Acropora eurystoma. Limnol. Oceangr 51, 1284–1293 (2006).
Suresh, V. R. & Mathew, K. J. Growth of staghorn coral Acropora aspera (Dana) (Scleractinia: Acropridae) in relation to environmental factors at Kavaratti atoll (Lakshadweep Islands), India. Indian Journal of Marine Sciences 24, 175–176 (1995).
Tunnicliffe, V. Caribbean staghorn coral populations: pre-hurricane Allen conditions in Discovery Bay, Jamaica. Bulletin of Marine Science 33, 132–151 (1983).
Anthony, K. R. N. & Hoegh Guldberg, O. Variation in coral photosynthesis, respiration and growth characteristics in contrasting light microhabitats: an analogue to plants in forest gaps and understoreys? Functional Ecology 17, 246–259 (2003).
Bythell, J. C. A total nitrogen and carbon budget for the elkhorn coral Acropora palmata (Lamarck). Proc 6th ICRS 2, 535–540 (1988).
Castillo, K. D. & Helmuth, B. S. T. Influence of thermal history on the response of Montastraea annularis to short-term temperature exposure. Marine Biology 148, 261–270 (2005).
Davies, P. S. Respiration in Some Atlantic Reef Corals in Relation to Vertical Distribution and Growth Form. Biological Bulletin 158, 187 (1980).
Gladfelter, E. H., Michel, G. & Sanfelici, A. Metabolic gradients along a branch of the reef coral Acropora palmata. Bulletin of Marine Science 44, 1166–1173 (1989).
Lesser, M. P. Depth-dependent photoacclimatization to solar ultraviolet radiation in the Caribbean coral Montastraea faveolata. Marine Ecology Progress Series 192, 137–151 (2000).
Lesser, M. P., Weis, V. M., Patterson, M. R. & Jokiel, P. L. Effects of morphology and water motion on carbon delivery and productivity in the reef coral, Pocillopora damicornis (Linnaeus): Diffusion barriers, inorganic carbon limitation, and biochemical plasticity. Journal of Experimental Marine Biology and Ecology 178, 153–179 (1994).
Porter, J. W. Reef Corals in Situ. In: Primary Productivity in the Sea, (ed. Falkowski, E.). pp. 403–410 (Springer, 1980).
Rex, A., Montebon, F. & Yap, H. T. Metabolic responses of the scleractinian coral Porites cylindrica Dana to water motion. I. Oxygen flux studies. Journal of Experimental Marine Biology and Ecology 186, 33–52 (1995).
Al Hammady, M. A. M. The effect of zooxanthellae availability on the rates of skeletal growth in the Red Sea coral Acropora hemprichii. The Egyptian Journal of Aquatic Research 39, 177–183 (2013).
Alibert, C. & Mc Culloch, M. T. Strontium/calcium ratios in modern porites corals From the Great Barrier Reef as a proxy for sea surface temperature: Calibration of the thermometer and monitoring of ENSO. Paleoceanography 12, 345–363 (1997).
Atkinson, M. J., Carlson, B. & Crow, G. L. Coral growth in high-nutrient, low-pH seawater: a case study of corals cultured at the Waikiki Aquarium, Honolulu, Hawaii. Coral Reefs 14, 215–223 (1995).
Bak, R. The growth of coral colonies and the importance of crustose coralline algae and burrowing sponges in relation with carbonate accumulation. Netherlands Journal of Sea Research 10, 285–337 (1976).
Bak, R. P. M. Neoplasia, regeneration and growth in the reef-building coral Acropora palmata. Mar. Biol. 77, 221–227 (1983).
Bak, R. P. M., Nieuwland, G. & Meesters, E. H. Coral growth rates revisited after 31 years: What is causing lower extension rates in Acropora palmata? Bulletin of Marine Science 84, 287–294 (2009).
Barnes, D. J. & Lough, J. M. The nature of skeletal density banding in scleractinian corals: fine banding and seasonal patterns. Journal of Experimental Marine Biology and Ecology 126, 119–134 (1989).
Bessat, F. & Buigues, D. Two centuries of variation in coral growth in a massive Porites colony from Moorea (French Polynesia): a response of ocean-atmosphere variability from south central Pacific. Palaeogeography, Palaeoclimatology, Palaeoecology 175, 381–392 (2001).
Bongiorni, L., Shafir, S., Angel, D. & Rinkevich, B. Survival, growth and gonad development of two hermatypic corals subjected to in situ fish-farm nutrient enrichment. Marine Ecology Progress Series 253, 137–144 (2003).
Bosscher, H. & Meesters, E. H. Depth related changes in the growth rate of Montastrea annularis. Proceedings of the Seventh International Coral Reef Symposium 1, 507–512 (1993).
Brown, B., Sya’rani, L. & Le Tissier, M. Skeletal form and growth in Acropora aspera (Dana) from the Pulau Seribu, Indonesia. Journal of Experimental Marine Biology and Ecology 86, 139–150 (1985).
Bruno, J. F. & Edmunds, P. J. Clonal Variation for Phenotypic Plasticity in the Coral Madracis Mirabilis. Ecology 78, 2177 (1997).
Buddemeier, R., Maragos, J. & Knutson, D. Radiographic studies of reef coral exoskeletons: Rates and patterns of coral growth. Journal of Experimental Marine Biology and Ecology 14, 179–199 (1974).
Burgess, S. N., Mc Culloch, M. T., Mortimer, G. E. & Ward, T. M. Structure and growth rates of the high-latitude coral: Plesiastrea versipora. Coral Reefs 28, 1005–1015 (2009).
Cantin, N. E., Cohen, A. L., Karnauskas, K. B., Tarrant, A. M. & Mc Corkle, D. C. Ocean Warming Slows Coral Growth in the Central Red Sea. Science 329, 322–325 (2010).
Carilli, J. E., Norris, R. D., Black, B., Walsh, S. M. & Mc Field, M. Century-scale records of coral growth rates indicate that local stressors reduce coral thermal tolerance threshold. Global Change Biology 16, 1247–1257 (2010).
Carricart Ganivet, J. P. Sea surface temperature and the growth of the West Atlantic reef-building coral Montastraea annularis. Journal of Experimental Marine Biology and Ecology 302, 249–260 (2004).
Castillo, K. D., Ries, J. B. & Weiss, J. M. Declining Coral Skeletal Extension for Forereef Colonies of Siderastrea siderea on the Mesoamerican Barrier Reef System, Southern Belize. PLoS ONE 6, e14615 (2011).
Chadwick Furman, N. E., Goffredo, S. & Loya, Y. Growth and population dynamic model of the reef coral Fungia granulosa Klunzinger, 1879 at Eilat, northern Red Sea. Journal of Experimental Marine Biology and Ecology 249, 199–218 (2000).
Chansang, H., Phongusuwan, N. & Boonyanate, P. Growth of corals under the effect of sedimentation along the northwest coast of Phuket, Thailand. Proceedings of the Seventh International Coral Reef Symposium 1, 241–248 (1992).
Charuchinda, M. & Chansang, H. Skeleton extension and banding formation of Porites lutea of fringing reefs along the south and west coasts of Phuket Island (Thailand). Proceedings of the Fifth International Coral Reef Symposium 6, 83–87 (1985).
Charuchinda, M. & Hylleberg, J. Skeletal extension of Acropora formosa at a fringing reef in the Andaman Sea. Coral Reefs 3, 215–219 (1984).
Clark, S. & Edwards, A. J. Coral transplantation as an aid to reef rehabilitation: evaluation of a case study in the Maldive Islands. Coral Reefs 14, 201–213 (1995).
Cobb, K. M., Charles, C. D. & Hunter, D. E. A central tropical Pacific coral demonstrates Pacific, Indian, and Atlantic decadal climate connections. Geophys. Res. Lett. 28, 2209–2212 (2001).
Corrège, T. et al. Interdecadal variation in the extent of South Pacific tropical waters during the Younger Dryas event. Nature 428, 927–929 (2004).
Cox, E. F. The effects of a selective corallivore on growth rates and competition for space between two species of Hawaiian corals. Journal of Experimental Marine Biology and Ecology 101, 161–174 (1986).
Crabbe, M. Scleractinian coral population size structures and growth rates indicate coral resilience on the fringing reefs of North Jamaica. Marine Environmental Research 67, 189–198 (2009).
Crabbe, M. Topography and spatial arrangement of reef-building corals on the fringing reefs of North Jamaica may influence their response to disturbance from bleaching. Marine Environmental Research 69, 158–162 (2010).
Crabbe, M. J. C. Coral Reef Populations in the Caribbean: Is There a Case for Better Protection against Climate Change? AJCC 02, 97–105 (2013).
Crabbe, M. J. C. & Smith, D. J. Sediment impacts on growth rates of Acropora and Porites corals from fringing reefs of Sulawesi, Indonesia. Coral Reefs 24, 437–441 (2005).
Crabbe, M. J. C., Wilson, M. E. J. & Smith, D. J. Quaternary corals from reefs in the Wakatobi Marine National Park, SE Sulawesi, Indonesia, show similar growth rates to modern corals from the same area. J. Quaternary Sci. 21, 803–809 (2006).
Crossland, C. J. Seasonal growth of Acropora cf. formosa and Pocillopora damicornis on a high latitude reef (Houtman Abrolhos, Western Australia). Proceedings of the Fourth International Coral Reef Symposium 1, 663–667 (1981).
Cruz-Piuun, G., Carricart-Ganivet, J. P. & Espinoza-Avalos, J. Monthly skeletal extension rates of the hermatypic corals Montastraea annularis and Montastraea faveolata: biological and environmental controls. Marine Biology 143, 491–500 (2003).
Custodio Iii, H. M. & Yap, H. T. Skeletal extension rates of Porites cylindrica and Porites (Synaraea) rus after transplantation to two depths. Coral Reefs 16, 267–268 (1997).
Dennison, W. C. & Barnes, D. J. Effect of water motion on coral photosynthesis and calcification. Journal of Experimental Marine Biology and Ecology 115, 67–77 (1988).
Dikou, A. Skeletal linear extension rates of the foliose scleractinian coral Merulina ampliata (Ellis & Solander, 1786) in a turbid environment. Marine Ecology 30, 405–415 (2009).
Dizon, R. & Yap, H. Coral responses in single- and mixed-species plots to nutrient disturbance. Marine Ecology Progress Series 296, 165–172 (2005).
Dodge, R. E. The natural growth records of reef building corals Doctoral dissertation. (Yale University, 237, 1978).
Domart Coulon, I. J. et al. Comprehensive characterization of skeletal tissue growth anomalies of the finger coral Porites compressa. Coral Reefs 25, 531–543 (2006).
Dustan, P. Growth and form in the reef-building coral Montastrea annularis. Marine Biology 33, 101–107 (1975).
Dustan, P. Distribution of zooxanthellae and photosynthetic chloroplast pigments of the reef-building coral Montastrea annularis Ellis and Solander in relation to depth on a west Indian coral reef. Bulletin of Marine Science 29, 79–95 (1979).
Eakin, C. M., Feingold, J. S. & Glynn, P. W. Oil refinery impacts on coral reef communities in Arub Proceedings of the Colloquium on Global Aspects of Coral Reefs, Health, Hazards and History (ed. Ginsburg R. N. ) 139–145 (Rosenstiel School of Marine and Atmospheric Science, University of Miami, 1994).
Edinger, E. N., Limmon, G. V., Jompa, J., Widjatmoko, W., Heikoop, J. M. & Risk, M. J. Normal Coral Growth Rates on Dying Reefs: Are Coral Growth Rates Good Indicators of Reef Health? Marine Pollution Bulletin 40, 404–425 (2000).
Fallon, S. J., Mc Culloch, M. T., Van Woesik, R. & Sinclair, D. J. Corals at their latitudinal limits: laser ablation trace element systematics in Porites from Shirigai Bay, Japan. Earth and Planetary Science Letters 172, 221–238 (1999).
Ferse, S. C. A. & Kunzmann, A. Effects of Concrete-Bamboo Cages on Coral Fragments: Evaluation of a Low-Tech Method Used in Artisanal Ocean-Based Coral Farming. Journal of Applied Aquaculture 21, 31–49 (2009).
Flannery, Jennifer A., Poore & Richard, Z. Sr/Ca Proxy Sea-Surface Temperature Reconstructions from Modern and Holocene Montastraea faveolata Specimens from the Dry Tortugas National Park, Florida, U.S.A. Journal of Coastal Research 63, 20–31 (2013).
Gateño, D., León, A., Barki, Y., Cortés, J. & Rinkevich, B. Skeletal tumor formations in the massive coral Pavona clavus. Marine Ecology Progress Series 258, 97–108 (2003).
Geneid, Y., Ebeid, M. & Hassan, M. Response to Increased Sediment Load by Three Coral Species from the Gulf of Suez (Red Sea). Journal of Fisheries and Aquatic Science 4, 238–245 (2009).
Gladfelter, E. H. Skeletal development in Acropora cervicornis. Coral Reefs 3, 51–57 (1984).
Gladfelter, E. H., Manahan, R. K. & Gladfelter, W. B. Growth rates of five reef-building corals in the Northeastern Caribbean. Bulletin of Marine Science 28, 728–734 (1978).
Glynn, P. W. Coral growth in upwelling and non-upwelling areas off Pacific coast of Panama. Journal of Marine Research 35, 567–585 (1977).
Glynn, P. W. El Nino-associated disturbance to coral reefs and post disturbance mortality by Acanthaster planci. Marine Ecology Progress Series 26, 295–300 (1985).
Glynn, P. W. Some Physical and Biological Determinants of Coral Community Structure in the Eastern Pacific. Ecological Monographs 46, 431 (1976).
Glynn, P. W. Aspects of the ecology of coral reefs in the western Atlantic region. In Biology and Geology of Coral Reefs, Vol. 2. Biology 1, (Eds. Jones O. A. & Endean R. ) pp. 271–324 (Academic Press, 1973).
Glynn, P. W. et al. Reef coral reproduction in the eastern Pacific: Costa Rica, Panamá, and Galápagos Islands (Ecuador). III. Agariciidae (Pavona gigantea and Gardineroseris planulata). Marine Biology 125, 579–601 (1996).
Glynn, P. W., Colley, S. B., Ting, J. H., Maté, J. L. & Guzmán, H. M. Reef coral reproduction in the eastern Pacific: Costa Rica, Panamá and Galápagos Islands (Ecuador). IV. Agariciidae, recruitment and recovery of Pavona varians and Pavona sp.a. Marine Biology 136, 785–805 (2000).
Glynn, P. W., Wellington, G. M. & Birkeland, C. Coral Reef Growth in the Galapagos: Limitation by Sea Urchins. Science 203, 47–49 (1979).
Glynn, P. W. & Stewart, R. H. Distribution of coral reefs in the Pearl Islands (Gulf of Panama) in relation to thermal conditions. Limnol. Oceangr. 18, 367–379 (1973).
Goffredo, S. et al. Inferred level of calcification decreases along an increasing temperature gradient in a Mediterranean endemic coral. Limnol. Oceanogr. 54, 930–937 (2009).
Gomez, E. D., Alcala, A. C., Yap, H. T., Alcala, L. C. & Aline, P. M. Growth studies of commercially important scleractinians. Proceedings of the 5th International Coral Reef Congress, Tahiti 6, 199–204 (1985).
Graus, R. R. & Mcintyre, I. G. Variation in growth forms of the reef coral Montastrea annularis (Ellis and Solander): a quantitative evaluation of growth response to light distribution using computer simulation. Smithsonian Contributions to Marine Sciences 12, 441–464 (1982).
Grigg, R. W. Depth limit for reef building corals in the Au’au Channel, S.E. Hawaii. Coral Reefs 25, 77–84 (2005).
Grigg, R. W. Darwin Point: A threshold for atoll formation. Coral Reefs 1, 29–34 (1982).
Grigg, R. W. Holocene coral reef accretion in Hawaii: a function of wave exposure and sea level history. Coral Reefs 17, 263–272 (1998).
Grottoli, A. G. Variability of stable isotopes and maximum linear extension in reef-coral skeletons at Kaneohe Bay, Hawaii. Marine Biology 135, 437–449 (1999).
Guzman, H. M. & Cortes, J. Growth rates of eight species of scleractinian corals in the Eastern Pacific (Costa Rica). Bulletin of Marine Science 44, 1186–1194 (1989).
Guzmán, H. M. & Tudhope, A. W. Seasonal variation in skeletal extension rate and stable isotopic (13C/12C and 18O/16O) composition in response to several environmental variables in the Caribbean reef coral Siderastrea siderea. Marine Ecology Progress Series 166, 109–118 (1998).
Guzmun, H. M., Jackson, J. B. C. & Weil, E. Short-term ecological consequences of a major oil spill on Panamanian subtidal reef corals. Coral Reefs 10, 1–12 (1991).
Harriott, V. J. Coral growth in subtropical eastern Australia. Coral Reefs 18, 281–291 (1999).
Harriott, V. J. Growth of the staghorn coral Acropora formosa at Houtman Abrolhos, Western Australia. Marine Biology 132, 319–325 (1998).
Heyward, A. J. & Collins, J. D. Growth and sexual reproduction in the scleractinian coral Montipora digitata (Dana). Mar. Freshwater Res. 36, 441 (1985).
Horta-Puga, G. & Carriquiry, J. D. The Last Two Centuries of Lead Pollution in the Southern Gulf of Mexico Recorded in the Annual Bands of the Scleractinian Coral Orbicella faveolata. Bull Environ Contam Toxicol 92, 567–573 (2014).
Hubbard, D. K. & Scaturo, D. Growth rates of seven species of scleractinian corals from Cane Bay and Salt River, St. Croix, USVI. Bulletin of Marine Science 36, 325–338 (1985).
Hudson, J. H. Long-term growth rates of Porites lutea before and after nuclear testing: Enewetak Atoll, Marshall Islands. Proceedings of the 5th International Coral Reef Symposium 6, 179–185 (1985).
Hudson, J. H. Growth rates in Montastrea annularis: a record of environmental change in Key Largo Coral Reef Marine Sanctuary, Florida. Bulletin of Marine Science 31, 444–459 (1981).
Hudson, J. H. & Goodwin, W. B. Restoration and growth rate of hurricane damaged pillar coral (Dendrogyra cylindrus) in the Key Largo National Marine Sanctuary, Florida. Proceedings of the 8th International Coral Reef Symposium, Panama 1, 567–570 (1997).
Hudson, J. H., Robbin, D. M. Effects of Drilling Mud on the Growth Rate of the Reef-Building Coral, Montastrea Annularis. In: Marine Environmental Pollution, I. Hydrocarbons, (ed. Richard A. ) 455–470 (Elsevier, 1980).
Hudson, J. H., Hanson, K. J., Halley, R. B. & Kindinger, J. L. Environmental implications of growth rate changes in Montastrea annularis: Biscayne National Park, Florida. Bulletin of Marine Science 54, 647–669 (1994).
Hughes, T. P. & Jackson, J. B. C. Population Dynamics and Life Histories of Foliaceous Corals. Ecological Monographs 55, 141 (1985).
Huston, M. Variation in coral growth rates with depth at Discovery Bay, Jamaica. Coral Reefs 4, 19–25 (1985).
Jimenez, C. & Cortes, J. Growth of seven species of scleractinian corals in an upwelling environment of the eastern Pacific (Golfo de Papagayo, Costa Rica). Bulletin of Marine Science 72, 187–198 (2003).
Jinendradasa, S. S. & Ekaratne, S. U. K. Linear extension of Acropora formosa (Dana) at selected reef locations in Sri Lanka. Proceedings of the Ninth International Coral Reef Symposium 1, 537–540 (2000).
Jokiel, P. L. & Tyler, W. A. Distribution of stony corals in Johnston Atoll lagoon. Proceedings of the Seventh International Coral Reef Symposium 2, 683–692 (1992).
Jokiel, P. L., Rodgers, K. S., Kuffner, I. B., Andersson, A. J., Cox, E. F. & Mackenzie, F. T. Ocean acidification and calcifying reef organisms: a mesocosm investigation. Coral Reefs 27, 473–483 (2008).
Kikuchi, R. K., Oliveira, M. D. & Leão, Z. M. Density banding pattern of the south western Atlantic coral Mussismilia braziliensis. Journal of Experimental Marine Biology and Ecology 449, 207–214 (2013).
Klein, R. & Loya, Y. Skeletal growth and density patterns of two Pontes corals from the Gulf of Eilat, Red Sea. Marine Ecology Progress Series 77, 253–259 (1991).
Knittweis, L., Jompa, J., Richter, C. & Wolff, M. Population dynamics of the mushroom coral Heliofungia actiniformis in the Spermonde Archipelago, South Sulawesi, Indonesia. Coral Reefs 28, 793–804 (2009).
Knutson, D. W., Buddemeier, R. W. & Smith, S. V. Coral Chronometers: Seasonal Growth Bands in Reef Corals. Science 177, 270–272 (1972).
Kotb, M. M. A. Growth rates of three reef-building coral species in the northern Red Sea, Egypt. Egyptian Journal of Aquatic Biology and Fisheries 5, 165–185 (2001).
Kružić, P., Sršen, P. & Benković, L. The impact of seawater temperature on coral growth parameters of the colonial coral Cladocora caespitosa (Anthozoa, Scleractinia) in the eastern Adriatic Sea. Facies 58, 477–491 (2012).
Lam, K. K. Y. Coral transplantation onto a stabilised puverised ash substratum. Asian Marine Biology 17, 25–41 (2000).
Larcom, E. A., McKean, D. L., Brooks, J. M. & Fisher, C. R. Growth rates, densities, and distribution of Lophelia pertusa on artificial structures in the Gulf of Mexico. Deep Sea Research Part I: Oceanographic Research Papers 85, 101–109 (2014).
Lewis, J. B., Axelson, F., Goodbody, I., Page, C. & Chislett, G. Comparative growth rates of some reef corals in the Caribbean. Marine Science Center 10, 1–26 (1968).
Linsley, B. K., Messier, R. G. & Dunbar, R. B. Assessing between-colony oxygen isotope variability in the coral Porites lobata at Clipperton Atoll. Coral Reefs 18, 13–27 (1999).
Lirman, D. Fragmentation in the branching coral Acropora palmata (Lamarck): growth, survivorship, and reproduction of colonies and fragments. Journal of Experimental Marine Biology and Ecology 251, 41–57 (2000).
Logan, A. & Tomascik, T. Extension growth rates in two coral species from high-latitude reefs of Bermuda. Coral Reefs 10, 155–160 (1991).
Logan, A., Yang, L. & Tomascik, T. Linear skeletal extension rates in two species of Diploria from high-latitude reefs in Bermuda. Coral Reefs 13, 225–230 (1994).
Manton, S. M. On the growth of the adult colony of Pocillopora bulbosa. Great Barrier Reef Expedition (1928–1929) Scientific Reports 3, 157–166 (1932).
Maragos, J. E. A study of the ecology of Hawaiian reef corals. PhD thesis (University of Hawaii, 1972).
Marsh, L. M. The Occurrence and Growth of Acropora in Extra-tropical Waters off Perth, Western Australia. Proceedings of the Seventh International Coral Reef Symposium, Guam, 1992 2, 1233–1238 (1992).
Martin, D. & Le Tissier, A. The growth and formation of branch tips of Pocillopora damicornis (Linnaeus). Journal of Experimental Marine Biology and Ecology 124, 115–131 (1988).
Mass, T. & Genin, A. Environmental versus intrinsic determination of colony symmetry in the coral Pocillopora verrucosa. Marine Ecology Progress Series 369, 131–137 (2008).
Mayor, A. G. Growth rate of Samoan corals. Publs. Carnegie Insta 340, 51–72 (1924).
Mendes, J. Timing of skeletal band formation in Montastraea annularis: Relationship to environmental and endogenous factors. Bulletin of Marine Science 75, 423–437 (2004).
Mendes, J. M. & Woodley, J. D. Effect of the 1995-1996 bleaching event on polyp tissue depth, growth, reproduction and skeletal band formation in Montastraea annularis. Marine Ecology Progress Series 235, 93–102 (2002).
Moore, W. S. & Krishnaswami, S. Coral growth rates using 228Ra and 210Pb. Earth and Planetary Science Letters 15, 187–190 (1972).
Mortensen, P. B., Rapp, H. T. & Båmstedt, U. Oxygen and carbon isotope ratios related to growth line patterns in skeletons of Lophelia pertusa (L.) (Anthozoa, Scleractinia): implications for determination of linear extension rate. Sarsia 83, 433–446 (1998).
Müller, A., Gagan, M. K. & Lough, J. M. Effect of early marine diagenesis on coral reconstructions of surface-ocean 13 C/ 12 C and carbonate saturation state. Global Biogeochem. Cycles 18, n/a–n/a (2004).
Neudecker, S. Growth and survival of scleractinian corals exposed to thermal effluents at Guam. Proc 4th Int Coral reef Symp 1, 173–180 (1981).
Oliver, J. K. Recurrent seasonal bleaching and mortality of corals on the Great Barrier Reef. Proceedings of the Fifth International Coral Reef Symposium 4, 201–206 (1985).
Osborne, M. C., Dunbar, R. B., Mucciarone, D. A., Sanchez-Cabeza, J. & Druffel, E. Regional calibration of coral-based climate reconstructions from Palau, West Pacific Warm Pool (WPWP). Palaeogeography, Palaeoclimatology, Palaeoecology 386, 308–320 (2013).
Putzold, J. Growth rhythms recorded in stable isotopes and density bands in the reef coral Porites lobata (Cebu, Philippines). Coral Reefs 3, 87–90 (1984).
Richmond, R. H. Energetic relationships and biogeographical differences among fecundity, growth and reproduction in the reef coral Pocillopora damicornis. Bulletin of Marine Science 41, 594–604 (1987).
Roberts, L. G. & Harriott, V. J. Can environmental records be extracted from coral skeletons from Moreton Bay, Australia, a subtropical, turbid environment? Coral Reefs 22, 517–522 (2003).
Rodgers, K., Cox, E. & Newtson, C. Effects of Mechanical Fracturing and Experimental Trampling on Hawaiian Corals. Environmental Management 31, 377–384 (2003).
Romano, S. L. Long-term effects of interspecific aggression on growth of the reef-building corals Cyphastrea ocellina (Dana) and Pocillopora damicomis (Linnaeus). Journal of Experimental Marine Biology and Ecology 140, 135–146 (1990).
Rosenfeld, M., Yam, R., Shemesh, A. & Loya, Y. Implication of water depth on stable isotope composition and skeletal density banding patterns in a Porites lutea colony: results from a long-term translocation experiment. Coral Reefs 22, 337–345 (2003).
Saenger, C., Cohen, A. L., Oppo, D. W. & Hubbard, D. Interpreting sea surface temperature from strontium/calcium ratios in Montastrea corals: Link with growth rate and implications for proxy reconstructions. Paleoceanography 23, n/a–n/a (2008).
Seo, I. et al. A skeletal Sr/Ca record preserved in Dipsastraea ( Favia ) speciosa and implications for coral Sr/Ca thermometry in mid-latitude regions. Geochemistry, Geophysics, Geosystems 14, 2873–2885 (2013).
Shaish, L., Levy, G., Katzir, G. & Rinkevich, B. Employing a highly fragmented, weedy coral species in reef restoration. Ecological Engineering 36, 1424–1432 (2010).
Shinn, E. A. Coral growth: an environmental indicator. Journal of Paleontology 40, 233–240 (1966).
Simpson, C. J. Ecology of scleractinian corals in the Dampier Archipelago, Western Australia. Technical Series No. 23. (Environmental Protection Authority 1988).
Stearn, C. W., Scoffin, T. P. & Martindale, W. Calcium carbonate budget of a fringing reef on the west coast of Barbados. Bulletin of Marine Science 27, 479–510 (1977).
Stimson, J. Wave-like outward growth of some table- and plate-forming corals, and a hypothetical mechanism. Bulletin of Marine Science 58, 301–313 (1996).
Stimson, J. The Effect of Shading by the Table Coral Acropora Hyacinthus on Understory Corals. Ecology 66, 40 (1985).
Suresh, V. R. & Mathew, K. J. Skeletal extension of staghorn coral Acropora formosa in relation to environment at Kavaratti atoll (Lakshadweep). Indian Journal of Marine Sciences 22, 176–179 (1993).
Suzuki, A., Hibino, K., Iwase, A. & Kawahata, H. Intercolony variability of skeletal oxygen and carbon isotope signatures of cultured Porites corals: Temperature-controlled experiments. Geochimica et Cosmochimica Acta 69, 4453–4462 (2005).
Suzuki, A., Kawahata, H., Tanimoto, Y., Tsukamoto, H., Gupta, L. P. & Yukino, I. Skeletal isotopic record of a Porites coral during the 1998 mass bleaching event. Geochem. J. 34, 321–329 (2000).
Tamura, T. & Hada, Y. Growth rate of reef-building corals inhabiting in the South Sea Islands. Sci. Rep. Tohoku. Imp. Univ. (Ser 4) 7, 433–455 (1932).
Tomascik, T. & Sander, F. Effects of eutrophication on reef-building corals. Mar. Biol. 87, 143–155 (1985).
Tomascik, T. Growth rates of two morphotypes of Montastrea annularis along a eutrophication gradient, Barbados, W.I. Marine Pollution Bulletin 21, 376–381 (1990).
Vaughan, T. W. Growth rate of the Floridian and Bahaman shoal-water corals. Year book - Carnegie Institution of Washington 14, 221–231 (1915).
Ward, S. The effect of damage on the growth, reproduction and storage of lipids in the scleractinian coral Pocillopora damicornis (Linnaeus). Journal of Experimental Marine Biology and Ecology 187, 193–206 (1995).
Wellington, G. M. An experimental analysis of the effects of light and zooplankton on coral zonation. Oecologia 52, 311–320 (1982).
Willis, B. L. Phenotypic plasticity versus phenotypic stability in the reef corals Turbinaria mesenterina and Pavona cactus. Proceedings of the 5th International Coral Reef Congress, Tahiti 4, 107–112 (1985).
Yap, H. T. & Gomez, E. D. Growth of Acropora pulchra. Mar. Biol. 87, 203–209 (1985).
Zhao, M. X., Yu, K. F., Zhang, Q. M., Shi, Q. & Roff, G. Age structure of massive Porites lutea corals at Luhuitou fringing reef (northern South China Sea) indicates recovery following severe anthropogenic disturbance. Coral Reefs 33, 39–44 (2013).
Gleason, D. F. Differential effects of ultraviolet radiation on green and brown morphs of the Caribbean coral Porites astreoides. Limnol. Oceangr 38, 1452–1463 (1993).
Jones, R. J. Zooxanthellae loss as a bioassay for assessing stress in corals. Marine Ecology Progress Series 149, 163–171 (1997).
Jones, R. J. & Yellowlees, D. Regulation and control of intracellular algae (=zooxanthellae) in hard corals. Philosophical Transactions of the Royal Society B: Biological Sciences 352, 457–468 (1997).
Roff, G., Kvennefors, E. C. E., Ulstrup, K. E., Fine, M. & Hoegh Guldberg, O. Coral disease physiology: the impact of Acroporid white syndrome on Symbiodinium. Coral Reefs 27, 373–377 (2007).
Stimson, J., Sakai, K. & Sembali, H. Interspecific comparison of the symbiotic relationship in corals with high and low rates of bleaching-induced mortality. Coral Reefs 21, 409–421 (2002).
Wilkerson, F. P., Kobayashi, D. & Muscatine, L. Mitotic index and size of symbiotic algae in Caribbean Reef corals. Coral Reefs 7, 29–36 (1988).
D’croz, L. & Maté, J. L. Experimental responses to elevated water temperature in genotypes of the reef coral Pocillopora damicornis from upwelling and non-upwelling environments in Panama. Coral Reefs 23, 473–483 (2004).
Edmunds, P. J. & Gates, R. D. Normalizing physiological data for scleractinian corals. Coral Reefs 21, 193–197 (2002).
Fitt, W. K., Spero, H. J., Halas, J., White, M. W. & Porter, J. W. Recovery of the coral Montastrea annularis in the Florida Keys after the 1987 Caribbean?bleaching event? Coral Reefs 12, 57–64 (1993).
Leuzinger, S., Anthony, K. R. N. & Willis, B. L. Reproductive energy investment in corals: scaling with module size. Oecologia 136, 524–531 (2003).
Porter, J. W., Fitt, W. K., Spero, H. J., Rogers, C. S. & White, M. W. Bleaching in reef corals: Physiological and stable isotopic responses. Proceedings of the National Academy of Sciences 86, 9342–9346 (1989).
Rodrigues, L. J. & Grottoli, A. G. Energy reserves and metabolism as indicators of coral recovery from bleaching. Limnol. Oceangr 52, 1874–1882 (2007).
Schlöder, C. & D’croz, L. Responses of massive and branching coral species to the combined effects of water temperature and nitrate enrichment. Journal of Experimental Marine Biology and Ecology 313, 255–268 (2004).
Apprill, A. M. & Gates, R. D. Recognizing diversity in coral symbiotic dinoflagellate communities. Molecular Ecology 16, 1127–1134 (2006).
Baillie, B. K., Belda-Baillie, C. A. & Maruyama, T. Conspecificity and indo-pacific distribution of symbiodinium genotypes (Dinophyceae) from giant clams. Journal of Phycology 36, 1153–1161 (2000).
Barshis, D. J. et al. Protein expression and genetic structure of the coral Porites lobata in an environmentally extreme Samoan back reef: does host genotype limit phenotypic plasticity? Molecular Ecology 19, 1705–1720 (2010).
Bielmyer, G. et al. Differential effects of copper on three species of scleractinian corals and their algal symbionts (Symbiodinium spp.) Aquatic Toxicology 97, 125–133 (2010).
Bongaerts, P. et al. Genetic Divergence across Habitats in the Widespread Coral Seriatopora hystrix and Its Associated Symbiodinium. PLoS ONE 5, e10871 (2010).
Brown, B. E., Dunne, R. P., Goodson, M. S. & Douglas, A. E. Marine ecology: Bleaching patterns in reef corals. Nature 404, 142–143 (2000).
Camargo, C. et al. Community involvement in management for maintaining coral reef resilience and biodiversity in southern Caribbean marine protected areas. Biodiversity and Conservation 18, 935–956 (2008).
Correa, A. M. S., Brandt, M. E., Smith, T. B., Thornhill, D. J. & Baker, A. C. Symbiodinium associations with diseased and healthy scleractinian corals. Coral Reefs 28, 437–448 (2009).
De Salvo, M. K. et al. Coral host transcriptomic states are correlated with Symbiodinium genotypes. Molecular Ecology 19, 1174–1186 (2010).
Dove, S. Scleractinian corals with photoprotective host pigments are hypersensitive to thermal bleaching. Marine Ecology Progress Series 272, 99–116 (2004).
Finney, J. C. et al. The Relative Significance of Host-Habitat, Depth, and Geography on the Ecology, Endemism, and Speciation of Coral Endosymbionts in the Genus Symbiodinium. Microb Ecol 60, 250–263 (2010).
Fitt, W. et al. Response of two species of Indo-Pacific corals, Porites cylindrica and Stylophora pistillata, to short-term thermal stress: The host does matter in determining the tolerance of corals to bleaching. Journal of Experimental Marine Biology and Ecology 373, 102–110 (2009).
Frade, P. R., De Jongh, F., Vermeulen, F., Van Bleijswijk, J. & Bak, R. P. M. Variation in symbiont distribution between closely related coral species over large depth ranges. Molecular Ecology 17, 691–703 (2007).
Frade, P. R., Englebert, N., Faria, J., Visser, P. M. & Bak, R. P. M. Distribution and photobiology of Symbiodinium types in different light environments for three colour morphs of the coral Madracis pharensis: is there more to it than total irradiance? Coral Reefs 27, 913–925 (2008).
Garren, M., Walsh, S. M., Caccone, A. & Knowlton, N. Patterns of association between Symbiodinium and members of the Montastraea annularis species complex on spatial scales ranging from within colonies to between geographic regions. Coral Reefs 25, 503–512 (2006).
Green, D. H., Edmunds, P. J., Pochon, X. & Gates, R. D. The effects of substratum type on the growth, mortality, and photophysiology of juvenile corals in St. John, US Virgin Islands. Journal of Experimental Marine Biology and Ecology 384, 18–29 (2010).
Hunter, C. L., Morden, C. W. & Smith, C. M. The utility of ITS sequences in assessing relationships among zooxanthellae and coral. Proceedings of the 8th International Coral Ref Symposium Vol 2, 1599–1602 (1997).
Iglesias-Prieto, R., Beltran, V. H., LaJeunesse, T. C., Reyes-Bonilla, H. & Thome, P. E. Different algal symbionts explain the vertical distribution of dominant reef corals in the eastern Pacific. Proceedings of the Royal Society B: Biological Sciences 271, 1757–1763 (2004).
Kemp, D. W., Fitt, W. K. & Schmidt, G. W. A microsampling method for genotyping coral symbionts. Coral Reefs 27, 289–293 (2007).
La Jeunesse, T. C. “Species” Radiations of Symbiotic Dinoflagellates in the Atlantic and Indo-Pacific Since the Miocene-Pliocene Transition. Molecular Biology and Evolution 22, 570–581 (2004).
La Jeunesse, T. C. et al. Closely related Symbiodinium spp. differ in relative dominance in coral reef host communities across environmental, latitudinal and biogeographic gradients. Marine Ecology Progress Series 284, 147–161 (2004).
La Jeunesse, T. C. et al. Specificity and stability in high latitude eastern Pacific coral-algal symbioses. Limnol. Oceangr 53, 719–727 (2008).
La Jeunesse, T. C. et al. Low symbiont diversity in southern Great Barrier Reef corals relative to those of the Caribbean. Limnol. Oceangr 48, 2046–2054 (2003).
La Jeunesse, T. C. et al. Long-standing environmental conditions, geographic isolation and host-symbiont specificity influence the relative ecological dominance and genetic diversification of coral endosymbionts in the genus Symbiodinium. Journal of Biogeography 37, 785–800 (2010).
La Jeunesse, T. C., Smith, R. T., Finney, J. & Oxenford, H. Outbreak and persistence of opportunistic symbiotic dinoflagellates during the 2005 Caribbean mass coral ‘bleaching’ event. Proceedings of the Royal Society B: Biological Sciences 276, 4139–4148 (2009).
La Jeunesse, T. C. et al. Host-symbiont recombination versus natural selection in the response of coral-dinoflagellate symbioses to environmental disturbance. Proceedings of the Royal Society B: Biological Sciences 277, 2925–2934 (2010).
La Jeunesse, T. et al. High diversity and host specificity observed among symbiotic dinoflagellates in reef coral communities from Hawaii. Coral Reefs 23, 596–603 (2004).
LaJeunesse, T. Diversity and community structure of symbiotic dinoflagellates from Caribbean coral reefs. Marine Biology 141, 387–400 (2002).
LaJeunesse, T. C. Investigating the biodiversity, ecology, and phylogeny of endosymbiotic dinoflagellates in the genus symbiodinium using the its region: in search of a “species” level marker. Journal of Phycology 37, 866–880 (2001).
Macdonald, A. H. H., Sampayo, E. M., Ridgway, T. & Schleyer, M. H. Latitudinal symbiont zonation in Stylophora pistillata from southeast Africa. Marine Biology 154, 209–217 (2008).
Pochon, X., Pawlowski, J., Zaninetta, L. & Rowan, R. High genetic diversity and relative specificity among Symbiodinium -like endosymbiotic dinoflagellates in soritid foraminiferans. Marine Biology 139, 1069–1078 (2001).
Pochon, X. et al. Comparison of endosymbiotic and free-living symbiodinium (dinophyceae) diversity in a Hawaiian reef environment. Journal of Phycology 46, 53–65 (2010).
Rodriguez Lanetty, M. & Hoegh Guldberg, O. Symbiont diversity within the widespread scleractinian coral Plesiastrea versipora, across the northwestern Pacific. Marine Biology 143, 501–509 (2003).
Sampayo, E. M., Franceschinis, L., Hoegh Guldberg, O. & Dove, S. Niche partitioning of closely related symbiotic dinoflagellates. Molecular Ecology 16, 3721–3733 (2007).
Sampayo, E. M., Ridgway, T., Bongaerts, P. & Hoegh Guldberg, O. Bleaching susceptibility and mortality of corals are determined by fine-scale differences in symbiont type. Proceedings of the National Academy of Sciences 105, 10444–10449 (2008).
Santos, S. R., Kinzie, R. A., Sakai, K. & Coffroth, M. A. Molecular Characterization of Nuclear Small Subunit (ISS)-rDNA Pseudogenes in a Symbiotic Dinoflagellate (Symbiodinium, Dinophyta). The Journal of Eukaryotic Microbiology 50, 417–421 (2003).
Santos, S. R., Taylor, D. J. & Coffroth, M. A. Genetic comparisons of freshly isolated versus cultured symbiotic dinoflagellates: implications for extrapolating to the intact symbiosis. Journal of Phycology 37, 900–912 (2001).
Savage, A. M. et al. Molecular diversity of symbiotic algae at the latitudinal margins of their distribution: dinoflagellates of the genus Symbiodinium in corals and sea anemones. Marine Ecology Progress Series 244, 17–26 (2002).
Silverstein, R. N., Correa, A., La Jeunesse, T. C. & Baker, A. C. Novel algal symbiont (Symbiodinium spp.) diversity in reef corals of Western Australia. Marine Ecology Progress Series 422, 63–75 (2011).
Smith, L. W., Wirshing, H. H., Baker, A. C. & Birkeland, C. Environmental versus genetic influences on growth rates of the corals Pocillopora eydouxi and Porites lobata (Anthozoa: Scleractinia). Pacific Science 62, 57–69 (2008).
Smith, R. T., Pinzón, J. H. & La Jeunesse, T. C. Symbiodinium (Dinophyta) diversity and stability in aquarium corals. Journal of Phycology 45, 1030–1036 (2009).
Stat, M. et al. Variation in Symbiodinium ITS2 Sequence Assemblages among Coral Colonies. PLoS ONE 6, e15854 (2011).
Stat, M. & Gates, R. D. Vectored introductions of marine endosymbiotic dinoflagellates into Hawaii. Biol Invasions 10, 579–583 (2007).
Stat, M., Loh, W. K. W., Hoegh Guldberg, O. & Carter, D. A. Symbiont acquisition strategy drives host–symbiont associations in the southern Great Barrier Reef. Coral Reefs 27, 763–772 (2008).
Stat, M., Pochon, X., Cowie, R. & Gates, R. D. Specificity in communities of Symbiodinium in corals from Johnston Atoll. Marine Ecology Progress Series 386, 83–96 (2009).
Thornhill, D. J., Fitt, W. K. & Schmidt, G. W. Highly stable symbioses among western Atlantic brooding corals. Coral Reefs 25, 515–519 (2006).
Thornhill, D. J., Kemp, D. W., Bruns, B. U., Fitt, W. K. & Schmidt, G. W. Correspondence between cold tolerance and temperate biogeography in a Western Atlantic symbiodinium (Dinophyta) lineage 1. Journal of Phycology 44, 1126–1135 (2008).
Thornhill, D. J., La Jeunesse, T. C., Kemp, D. W., Fitt, W. K. & Schmidt, G. W. Multi-year, seasonal genotypic surveys of coral-algal symbioses reveal prevalent stability or post-bleaching reversion. Marine Biology 148, 711–722 (2005).
Thornhill, D. J., Xiang, Y. U., Fitt, W. K. & Santos, S. R. Reef Endemism, Host Specificity and Temporal Stability in Populations of Symbiotic Dinoflagellates from Two Ecologically Dominant Caribbean Corals. PLoS ONE 4, e6262 (2009).
Van Oppen, M. J. H., Bongaerts, P., Underwood, J. N., Peplow, L. M. & Cooper, T. F. The role of deep reefs in shallow reef recovery: an assessment of vertical connectivity in a brooding coral from west and east Australia. Molecular Ecology 20, 1647–1660 (2011).
Chen, C. A., Wang, J. T., Fang, L. S. & Yang, Y. W. Fluctuating algal symbiont communities in Acropora palifera (Scleractinia: Acroporidae) from Taiwan. Marine Ecology Progress Series 295, 113–121 (2005).
De Salvo, M. K., Sunagawa, S., Voolstra, C. R. & Medina, M. Transcriptomic responses to heat stress and bleaching in the elkhorn coral Acropora palmata. Marine Ecology Progress Series 402, 97–113 (2010).
Fagoonee, I. The Dynamics of Zooxanthellae Populations: A Long-Term Study in the Field. Science 283, 843–845 (1999).
Iguchi, A. et al. Effects of acidified seawater on coral calcification and symbiotic algae on the massive coral Porites australiensis. Marine Environmental Research 73, 32–36 (2012).
Li, S. et al. Interspecies and spatial diversity in the symbiotic zooxanthellae density in corals from northern South China Sea and its relationship to coral reef bleaching. Chinese Science Bulletin 53, 295–303 (2008).
Middlebrook, R., Anthony, K. R. N., Hoegh Guldberg, O. & Dove, S. Heating rate and symbiont productivity are key factors determining thermal stress in the reef-building coral Acropora formosa. Journal of Experimental Biology 213, 1026–1034 (2010).
Middlebrook, R., Hoegh Guldberg, O. & Leggat, W. The effect of thermal history on the susceptibility of reef-building corals to thermal stress. Journal of Experimental Biology 211, 1050–1056 (2008).
Okamoto, M., Nojima, S., Furushima, Y. & Nojima, H. Evaluation of coral bleaching condition in situ using an underwater pulse amplitude modulated fluorometer. Fisheries Science 71, 847–854 (2005).
Quan Young, L. I. & Espinoza Avalos, J. Reduction of zooxanthellae density, chlorophyll a concentration, and tissue thickness of the coral Montastraea faveolata (Scleractinia) when competing with mixed turf algae. Limnol. Oceanogr. 51, 1159–1166 (2006).
Roder, C. et al. Metabolic plasticity of the corals Porites lutea and Diploastrea heliopora exposed to large amplitude internal waves. Coral Reefs 30, 57–69 (2011).
Stimson, J. & Kinzie, R. A. The temporal pattern and rate of release of zooxanthellae from the reef coral Pocillopora damicornis (Linnaeus) under nitrogen-enrichment and control conditions. Journal of Experimental Marine Biology and Ecology 153, 63–74 (1991).
Strychar, K. B., Coates, M. & Sammarco, P. W. Loss of Symbiodinium from bleached Australian scleractinian corals (Acropora hyacinthus, Favites complanata and Porites solida). Mar. Freshwater Res. 55, 135 (2004).
Thornhill, D. J. et al. A Connection between Colony Biomass and Death in Caribbean Reef-Building Corals. PLoS ONE 6, e29535 (2011).
Ulstrup, K. E., Berkelmans, R., Ralph, P. J. & Van Oppen, M. Variation in bleaching sensitivity of two coral species across a latitudinal gradient on the Great Barrier Reef: the role of zooxanthellae. Marine Ecology Progress Series 314, 135–148 (2006).
Loya, Y. et al. Coral bleaching: the winners and the losers. Ecology Letters 4, 122–131 (2001).
Arrigoni, R. et al. Forgotten in the taxonomic literature: resurrection of the scleractinian coral genus Sclerophyllia (Scleractinia, Lobophylliidae) from the Arabian Peninsula and its phylogenetic relationships. Systematics and Biodiversity 13, 140–163 (2014).
Benzoni, F. Psammocora albopicta sp nov., a new species of Scleractinian Coral from the Indo-West Pacific (Scleractinia; Siderastreidae). Zootaxa 1358, 49–57 (2006).
Benzoni, F. Echinophyllia tarae sp. n. (Cnidaria, Anthozoa, Scleractinia), a new reef coral species from the Gambier Islands, French Polynesia. ZooKeys 318, 59–79 (2013).
Benzoni, F., Arrigoni, R., Waheed, Z., Stefani, F. & Hoeksema, B. W. Phylogenetic relationships and revision of the genus Blastomussa (Cnidaria: Anthozoa: Scleractinia) with description of a new species. Raffles Bulletin of Zoology 62, 358–378 (2014).
Benzoni, F. & Stefani, F. Porites fontanesii, a new species of hard coral (Scleractinia, Poritidae) from the southern Red Sea, the Gulf of Tadjoura, and the Gulf of Aden, and its phylogenetic relationships within the genus. Zootaxa 3447, 56–68 (2012).
Claereboudt, M. R. Reef corals and coral reefs of the Gulf of Oman. (Al-Roya Publishing, 2006).
Ditlev, H. New Scleractinian corals (Cnidaria: Anthozoa) from Sabah, North Borneo. Description of one new genus and eight new species, with notes on their taxonomy and ecology. Zoologische Mededelingen Leiden 77, 193–219 (2003).
Durham, J. W. Corals from the Gulf of California and the North Pacific coast of America. Geological Society of America Memoirs 20, 1–62 (1947).
Forsman, Z. H. & Birkeland, C. Porites randalli: A new coral species (Scleractinia, Poritidae) from American Samoa. Zootaxa 2244, 51–59 (2009).
Head, S. M. An undescribed species of Merulina and a new genus and species of siderastreid coral from the Red Sea. Journal of Natural History 17, 419–435 (1983).
Hoeksema, B. The “Fungia patella group” (Scleractinia, Fungiidae) revisited with a description of the mini mushroom coral Cycloseris boschmai sp. ZooKeys 371, 57–84 (2014).
Hoeksema, B. W. Attached mushroom corals (Scleractinia: Fungiidae) in sediment-stressed reef conditions at Singapore, including a new species and a new record. Raffles Bulletin of Zoology S22, 81–90 (2009).
Kitahara, M. V. & Cairns, S. D. A revision of the genus Deltocyathus Milne Edwards & Haime, 1848 (Scleractinia, Caryophylliidae) from New Caledonia, with the description of a new species. Zoosystema 31, 233–248 (2009).
Kitahara, M. V., Cairns, S. D. & Miller, D. J. Monophyletic origin of Caryophyllia (Scleractinia, Caryophylliidae), with descriptions of six new species. Systematics and Biodiversity 8, 91–118 (2010).
Kitano, Y. F. et al. A Phylogeny of the Family Poritidae (Cnidaria, Scleractinia) Based on Molecular and Morphological Analyses. PLoS ONE 9, e98406 (2014).
Latypov, Y. Y. Favia camranensis sp. n. (Scleractinia: Faviidae), a new coral species from Southern Vietnam. Russian Journal of Marine Biology 39, 223–224 (2013).
Locke, J. M., Weil, E. & Coates, K. A. Newly documented species of Madracis (Scleractinia: Pocilloporidae) from the Caribbean. Proceedings of the Biological Society of Washington 120, 214–226 (2007).
Pichon, M., Chuang, Y. Y. & Chen, C. A. Pseudosiderastrea formosa sp nov (Cnidaria: Anthozoa: Scleractinia) a New Coral Species Endemic to Taiwan. Zool Stud 51, 93–98 (2012).
Quelch, J. J. Report of the reef-corals collected by the H.M.S. Challenger during the years 1873–1976. Report on the Scientific Results of the Voyage of HMS Challenger (1873-76), Zoology 16, 1–203 (1886).
Schmidt Roach, S., Miller, K. J. & Andreakis, N. Pocillopora aliciae: a new species of scleractinian coral (Scleractinia, Pocilloporidae) from subtropical Eastern Australia. Zootaxa 3626, 576 (2013).
Schmidt Roach, S., Miller, K. J., Lundgren, P. & Andreakis, N. With eyes wide open: a revision of species within and closely related to the Pocillopora damicornis species complex (Scleractinia; Pocilloporidae) using morphology and genetics. Zool J Linn Soc. 170, 1–33 (2014).
Sheppard, C. R. C. Coral species of the Indian Ocean and adjacent seas: a synonymized compilation and some regional distributional patterns. Atoll Research Bulletin 307, 1–32 (1987).
Terraneo, T. I. et al. Pachyseris inattesa sp. n. (Cnidaria, Anthozoa, Scleractinia): a new reef coral species from the Red Sea and its phylogenetic relationships. ZooKeys 433, 1–30 (2014).
Vaughan, T. W. Some madreporarian corals from French Somaliland, East Africa, collected by Dr. Charles Gravier. Proceedings of the United States National Museum 32, 249–266 (1907).
Vermeij, M. J. A., Diekmann, O. E. & Bak, R. P. M. New species of scleractinian coral (Cnidaria, anthozoa), Madracis carmabi n. sp from the Caribbean. Bulletin of Marine Science 73, 679–684 (2003).
Wallace, C. C., Done, B. J. & Muir, P. R. Revision and catalogue of worldwide staghorn corals Acropora and Isopora (Scleractinia: Acroporidae) in the Museum of Tropical Queensland. Memoirs of the Queensland Museum 57, 1–255 (2012).
Abe, N. Ecological studies on Rhizopsammia minuta var. mutsuensis. Jubilee published in the commemoration of Prof. H. Yabe 60th Birthday 1, 175–187 (1939).
Ayre, D. J. & Resing, J. M. Sexual and asexual production of planulae in reef corals. Mar. Biol. 90, 187–190 (1986).
Babcock, R. C., Baird, A. H., Piromvaragorn, S., Thomson, D. P. & Willis, B. L. Identification of scleractinian coral recruits from Indo-Pacific reefs. Zoological Studies 42, 211–226 (2003).
Babcock, R. C. et al. Synchronous spawnings of 105 scleractinian coral species on the Great Barrier Reef. Mar. Biol. 90, 379–394 (1986).
Babcock, R. C. & Heyward, A. J. Larval development of certain gamete-spawning scleractinian corals. Coral Reefs 5, 111–116 (1986).
Babcock, R. C., Wills, B. L. & Simpson, C. J. Mass spawning of corals on a high latitude coral reef. Coral Reefs 13, 161–169 (1994).
Baird, A. H., Babcock, R. C. & Mundy, C. P. Habitat selection by larvae influences the depth distribution of six common coral species. Marine Ecology Progress Series 252, 289–293 (2003).
Baird, A. H. et al. Coral reproduction on the world’s southernmost reef at Lord Howe Island, Australia. Aquat. Biol. 23, 275–284 (2015).
Baird, A. H., Pratchett, M. S., Gibson, D. J., Koziumi, N. & Marquis, C. P. Variable palatability of coral eggs to a planktivorous fish. Mar. Freshwater Res. 52, 865–868 (2001).
Barros, M. M. L. D. & Pires, D. D. O. Colony size-frequency distributions among different populations of the scleractinian coral Siderastrea stellata in Southwestern Atlantic: implications for life history patterns. Braz. J. Oceanogr 54, 213–223 (2006).
Bastidas, C. et al. Coral mass- and split-spawning at a coastal and an offshore Venezuelan reefs, southern Caribbean. Hydrobiologia 541, 101–106 (2005).
Beauchamp, K. A. Gametogenesis, brooding and planulation in laboratory populations of a temperate scleractinian coral Balanophyllia elegans maintained under contrasting photoperiod regimes. Invertebrate Reproduction & Development 23, 171–182 (1993).
Bermas, N. A., Aliño, P. M., Atrigenio, M. P. & Uychiaoco, A. Observations on the reproduction of scleractinian and soft corals in the Philippines. Proceedings of the 7th International Coral Reef Symposium 1, 443–447 (1992).
Borneman, E. H. Reproduction in aquarium corals. Proceeding of the 10th International Coral Reef Symposium, Okinawa 1, 50–60 (2006).
Bouwmeester, J. et al. Multi-species spawning synchrony within scleractinian coral assemblages in the Red Sea. Coral Reefs 34, 65–77 (2014).
Brooke, S. & Young, C. M. Reproductive ecology of a deep-water scleractinian coral, Oculina varicosa, from the southeast Florida shelf. Continental Shelf Research 23, 847–858 (2003).
Cairns, S. D. Scleractinia of the Temperate North Pacific. Smithsonian Contributions to Zoology (1994).
Calderon, E. N., Castro, C. B. & Pires, D. O. Natacao, assentamento e metamorfose de planulas do coral Favia gravida Verrill, 1868 (Cnidaria, Scleractinia) 1868 (Cnidaria, Scleractinia). Boletim do Meseu Nacional 429, 1–12 (2000).
Carroll, A., Harrison, P. & Adjeroud, M. Sexual reproduction of Acropora reef corals at Moorea, French Polynesia. Coral Reefs 25, 93–97 (2005).
Colley, S. B., Feingold, J. S., Peña, J. & Glynn, P. W. Reproductive ecology of Diaseris distorta (Michelin) (Fungiidae) in the Galápagos Islands, Ecuador. Proceedings of the 9th International Coral Reef Symposium 1, 373–379 (2002).
Dai, C. F., Soong, T. K. & Fan, T. Y. Sexual reproduction of corals in northern and southern Taiwan. Proceedings of the 7th International Coral Reef Symposium, Guam 1, 448–454 (1992).
de Graaf, M., Geertjes, G. J. & Videler, J. J. Observations on spawning of scleractinian corals and other invertebrates on the reefs of Bonaire (Netherland Antilles Caribbean). Bulletin of marine science 64, 189–194 (1999).
Delvoye, L. Gametogenesis and gametogenic cycles in Agaricia agaricites (L) and Agaricia humilis Verrill and notes on gametogenesis in Madracis mirabilis (Duchassaing & Michelotti)(Scleractinia). Uitgaven Natuurwetenschappelijke Studiekring voor Suriname en de Nederlandse Antillen 123, 101–134 (1988).
Duerden, J. E. Aggregated Colonies in Madreporarian Corals. The American Naturalist 36, 461 (1902).
Fadlallah, Y. Synchronous spawning of Acropora clathrata coral colonies from the western Arabian Gulf (Saudi Arabia). Bulletin of marine science 59, 209 (1996).
Fadlallah, Y. The reproductive biology of three species of corals from central California. University of California santa cruz, (1981).
Fadlallah, Y. H. Sexual reproduction, development and larval biology in scleractinian corals. Coral Reefs 2, 129–150 (1983).
Fadlallah, Y. H. & Pearse, J. S. Sexual reproduction in solitary corals: Synchronous gametogenesis and broadcast spawning in Paracyathus stearnsii. Mar. Biol. 71, 233–239 (1982).
Fadlallah, Y., Lindo, R. T. & Lennon, D. J. Annual synchronous spawning event in Acropora species from the Arabian Gulf. Proceedings of the 7th International Coral Reef Symposium, Guam 1, 501 (1992).
Fan, T. Y. et al. Diel patterns of larval release by five brooding scleractinian corals. Marine Ecology Progress Series 321, 133–142 (2006).
Fiene-Severns, P. A note on synchronous spawning in the reef coral Pocillopora meandrina at Molokini Islet, Hawaii. Reproduction in Reef Corals Results of the 1997 Edwin W. Pauley Summer Program in Marine Biology 4, 22–24 (1998).
Fisk, D. A. Studies of two free-living corals and their common sipunculan associate at Wistari Reef (Great Barrier Reef). (University of Queensland, Australia, 1981).
Glynn, P. W. & Ault, J. S. A biogeographic analysis and review of the far eastern Pacific coral reef region. Coral Reefs 19, 1–23 (2000).
Glynn, P. W. et al. Reef coral reproduction in the eastern Pacific: Costa Rica, Panamá, and Galápagos Islands (Ecuador). II. Poritidae. Marine Biology 118, 191–208 (1994).
Glynn, P. W. et al. Reef coral reproduction in the equatorial eastern Pacific: Costa Rica, Panamá, and the Galápagos Islands (Ecuador). VII. Siderastreidae, Psammocora stellata and Psammocora profundacella. Marine Biology 159, 1917–1932 (2012).
Glynn, P. W. et al. Reef coral reproduction in the eastern Pacific: Costa Rica, Panama, and Galapagos Islands (Ecuador). Mar. Biol. 109, 355–368 (1991).
Goffredo, S., Airi, V., Radetić, J. & Zaccanti, F. Sexual reproduction of the solitary sunset cup coral Leptopsammia pruvoti (Scleractinia, Dendrophylliidae) in the Mediterranean. 2. Quantitative aspects of the annual reproductive cycle. Marine Biology 148, 923–931 (2006).
Goffredo, S. & Telo, T. Hermaphroditism and brooding in the solitary coral balanophyllia Europaea (Cnidaria, anthozoa, scleractinia). Italian Journal of Zoology 65, 159–165 (1998).
Golbuu, Y. & Richmond, R. H. Substratum preferences in planula larvae of two species of scleractinian corals, Goniastrea retiformis and Stylaraea punctata. Marine Biology 152, 639–644 (2007).
Guest, J. R., Baird, A. H., Goh, B. P. L. & Chou, L. M. Sexual systems in scleractinian corals: an unusual pattern in the reef-building species Diploastrea heliopora. Coral Reefs 31, 705–713 (2012).
Guest, J. R., Baird, A. H., Goh, B. P. & Chou, L. M. Seasonal reproduction in equatorial reef corals. Invertebrate Reproduction & Development 48, 207–218 (2005).
Hagman, D. K., Gittings, S. R. & Vize, P. D. Fertilization in broadcast spawning corals of the Flower Garden Banks National Marine Sanctuary. Gulf of Mexico science 16, 180–187 (1998).
Hanafy, M. H., Aamer, M. A., Habib, M., Rouphael, A. B. & Baird, A. H. Synchronous reproduction of corals in the Red Sea. Coral Reefs 29, 119–124 (2009).
Harrison, P. L. Pseudo-gynodioecy: An unusual breeding system in the scleractinian coral Galaxea fascicularis. Proceedings of the 6th International Coral Reef Symposium 2, 699–705 (1988).
Harrison, P. L. et al. Mass Spawning in Tropical Reef Corals. Science 223, 1186–1189 (1984).
Hayashibara, T. et al. Patterns of coral spawning at Akajima Island, Okinawa, Japan. Marine Ecology Progress Series 101, 253–262 (1993).
Heltzel, P. & Babcock, R. Sexual reproduction, larval development and benthic planulae of the solitary coral Monomyces rubrum (Scleractinia: Anthozoa). Marine Biology 140, 659–667 (2002).
Heyward, A. J. Sexual reproduction in five species of the coral Montipora. In: Coral Reef Population Biology (eds. Jokiel, P.L., Richmond, R.H. & Rogers, R.A.). Hawaii Institute of Marine Biology Technical Report 37, 170–178 ( 1986).
Heyward, A. J. Chromosomes of the coral Goniopora lobata (Anthozoa: Scleractinia). Heredity 55, 269–271 (1985).
Hizi Degany, N., Meroz Fine, E., Shefer, S. & Ilan, M. Tale of two colors: Cladopsammia gracilis (Dendrophylliidae) color morphs distinguished also by their genetics and ecology. Marine Biology 151, 2195–2206 (2007).
Hodgson, G. Potential gamete wastage in synchronously spawning corals due to hybrid inviability. Proc. 6th. Int. Coral Reef Symp 2, 707–714 (1988).
Hoke, S. M., Colley, S. B. & Feingold, J. S. Sexual reproduction in the elliptical star coral Dichocoenis stokes (Poster). Presented at ISRS European Meeting, Cambridge, (2002).
Johnson, K. Population dynamics of a free-living coral: recruitment, growth and survivorship of Manicina areolata (Linnaeus) on the Caribbean coast of Panama. Journal of Experimental Marine Biology and Ecology 164, 171–191 (1992).
Kawaguti, S. On the physiology of reef corals. V. Tropisms of coral planulae considered as a factor of distribution on the reef. Palao. Trop. Bio. Stat. Stud. 2, 319–328 (1941).
Kenyon, J. C. Latitudinal Differences between Palau and Yap in Coral Reproductive Synchrony. Pacific Science 49, 156–164 (1995).
Kinzie, R. A. III. Spawning in the reef corals Pocillopora verrucosa and P. eydouxi at Sesoko island, Okinawa. Galaxea 11, 93–105 (1993).
Knowlton, N., Maté, J. L., Guzmán, H. M., Rowan, R. & Jara, J. Direct evidence for reproductive isolation among the three species of the Montastraea annularis complex in Central America (Panamá and Honduras). Marine Biology 127, 705–711 (1997).
Kojis, B. L. Sexual reproduction in Acropora (Isopora) species (Coelenterata: Scleractinia). Mar. Biol. 91, 291–309 (1986).
Kojis, B. L. & Quinn, N. J. Reproductive strategies in four species of Porites (Scleractinia). Proceedings of the 4th International Coral Reef Symposium, Manila 2, 145–151 (1982).
Kojis, B. L. & Quinn, N. J. Reproductive Ecology of Two Faviid Corals (Coelenterata: Scleractinia). Marine Ecology Progress Series 8, 251–255 (1982).
Kolinski, S. P. & Cox, E. F. An Update on Modes and Timing of Gamete and Planula Release in Hawaiian Scleractinian Corals with Implications for Conservation and Management. Pacific Science 57, 17–27 (2003).
Kongjandtre, N., Ridgway, T., Ward, S. & Hoegh Guldberg, O. Broadcast spawning patterns of Favia species on the inshore reefs of Thailand. Coral Reefs 29, 227–234 (2009).
Krupp, D. A. Sexual reproduction and early development of the solitary coral Fungia scutaria (Anthozoa: Scleractinia). Coral Reefs 2, 159–164 (1983).
Kružić, P., Žuljević, A. & Nikolić, V. Spawning of the colonial coral Cladocora caespitosa (Anthozoa, Scleractinia) in the Southern Adriatic Sea. Coral Reefs 27, 337–341 (2007).
Lacaze-Duthiers, H. Faune du Golfe du Lion: Coralliares zoanthaires sclerodermes. Arch. Zool. Exp. Gen. Ser. 3, 1–249 (1897).
Lacaze-Duthiers, H. Developement des coralliaires. Actinaires a Polypiers. Arch. Zool. Exp. Gen. 2, 269–348 (1873).
Mangubhai, S. & Harrison, P. L. Seasonal patterns of coral reproduction on equatorial reefs in Mombasa, Kenya. Proceeding of the 10th International Coral Reef Symposium, Okinawa 1, 106–114 (2006).
Marquis, C. P., Baird, A. H., De Nys, R., Holmström, C. & Koziumi, N. An evaluation of the antimicrobial properties of the eggs of 11 species of scleractinian corals. Coral Reefs 24, 248–253 (2005).
Marshall, S. N. & Stephenson, T. A. The Breeding of Reef Animals. Part. 1. The Corals. Scientific Reports: Great Barrier Reef Expedition 3, 219–245 (1933).
Mezaki, T. et al. Spawning patterns of high latitude scleractinian corals from 2002 to 2006 at Nishidomari, Otsuki, Kochi, Japan. Kuroshio Biosphere 3, 33–47 (2007).
Morse, D. E., Hooker, N., Morse, A. N. & Jensen, R. A. Control of larval metamorphosis and recruitment in sympatric agariciid corals. Journal of Experimental Marine Biology and Ecology 116, 193–217 (1988).
Moseley, H. N. Report on Certain Hydroid, Alcyonanan. and Madreporarian Corals Procured during the Voyage of H. M. S. Challenger, in the Years 1873-1876. Zoology 2, 1–248 (1881).
Nakano, Y. & Yamazato, K. Ecological study of reproduction of Oulastrea crispata in Okinawa. Zool Sci. 9, 1292 (1992).
Neves, E. Histological Analysis of Reproductive Trends of Three Porites Species from Kane’ohe Bay, Hawai. Pacific Science 54, 195–200 (2000).
Penland, L., Kloulechad, J., Idip, D. & Van Woesik, R. Coral spawning in the western Pacific Ocean is related to solar insolation: evidence of multiple spawning events in Palau. Coral Reefs 23, 133–140 (2004).
Pinzon, J. H. A multivariate review of the taxonomy of the scleractinian genus Meandrina (Lamarck, 1801) in the Caribbean. University of Puerto Rico (2004).
Pires, D. O., Castro, C. B. & Ratto, C. C. Reproduction of the solitary coral Scolymia wellsi Laborel (Cnidaria, Scleractinia) from the Abrolhos reef complex, Brazil. Proceedings of the 9th International Coral Reef Symposium, Bali 1, 382–384 (2000).
Pires, D. O., Castro, C. B. & Ratto, C. C. Reef coral reproduction in the Abrolhos Reef Complex, Brazil: the endemic genus Mussismilia. Marine Biology 135, 463–471 (1999).
Richmond, R. H. & Hunter, C. L. Reproduction and recruitment of corals: comparisons among the Caribbean, the Tropical Pacific, and the Red Sea. Marine Ecology Progress Series 60, 185–203 (1990).
Sakai, K. Gametogenesis, spawning, and planula brooding by the reef coral Goniastrea aspera (Scleractinia) in Okinawa, Japan. Marine Ecology Progress Series 151, 67–72 (1997).
Shlesinger, Y., Goulet, T. L. & Loya, Y. Reproductive patterns of scleractinian corals in the northern Red Sea. Marine Biology 132, 691–701 (1998).
Shlesinger, Y. & Loya, Y. Coral Community Reproductive Patterns: Red Sea Versus the Great Barrier Reef. Science 228, 1333–1335 (1985).
Simpson, C. J. Mass spawning of scleractinian corals in the Dampier Archipelago and the implications for management of coral reefs in Western Australia. Dep. Conserv. Environ. West. Aust. Bull., Perth. Report 244 (1985).
Soong, K. Sexual Reproductive Patterns of Shallow-water Reef Corals in Panama. Bulletin of marine science 9, 832–846 (1991).
Stobart, B., Babcock, R. C. & Willis, B. L. Biannual spawning of three species of scleractinian coral from the Great Barrier Reef. Proc. 7th. Int. Coral Reef Symp 494–499 (1992).
Szmant Froelich, A., Yevich, P. & Pilson, M. E. Q. Gametogenesis and Early Development of the Temperate Coral Astrangia danae (Anthozoa: Scleractinia). Biological Bulletin 158, 257 (1980).
Szmant-Froelich, A. Reef coral reproduction: diversity and community patterns. Advances in Reef Science. Adv. Reef Sci. Joint Meet. Alt. Reef Comm. and Int. Soc. Reef Studies, Miami, Oct 26–28, pp 122–123 (1984).
Szmant-Froelich, A., Reutter, M. & Riggs, L. Sexual reproduction of Favia fragum (Esper): Lunar patterns of gametogenesis, embryogenesis and planulation in Puerto Rico. Bulletin of Marine Science 37, 880–892 (1985).
Tomascik, T. & Sander, F. Effects of eutrophication on reef-building corals. Mar. Biol. 94, 77–94 (1987).
Tranter, P. R. G., Nicholson, D. N. & Kinchington, D. A Description of Spawning and Post-Gastrula Development of the Cool Temperate Coral, Caryophyllia Smithi. Journal of the Marine Biological Association of the United Kingdom 62, 845 (1982).
Vargas Ángel, B., Colley, S. B., Hoke, S. M. & Thomas, J. D. The reproductive seasonality and gametogenic cycle of Acropora cervicornis off Broward County, Florida, USA. Coral Reefs 25, 110–122 (2005).
Vermeij, M., Sampayo, E., Bröker, K. & Bak, R. Variation in planulae release of closely related coral species. Marine Ecology Progress Series 247, 75–84 (2003).
Vollmer, S. V. Hybridization and the Evolution of Reef Coral Diversity. Science 296, 2023–2025 (2002).
von Koch, G. Entwicklung von Caryophyllia cyathus. Mitt. Zool. Stat. Neapel. Bd. 12, 755–772 (1897).
Wallace, C. Systematics of Coral Genus Acropora: Implications of the New Biological Findings for Species Concepts. Annual Review of Ecology and Systematics 25, 237–262 (1994).
Wallace, C. C. Reproduction, recruitment and fragmentation in nine sympatric species of the coral genus Acropora. Marine Biology 88, 217–233 (1985).
Wallace, C. C., Chen, C. A., Fukami, H. & Muir, P. R. Recognition of separate genera within Acropora based on new morphological, reproductive and genetic evidence from Acropora togianensis, and elevation of the subgenus Isopora Studer, 1878 to genus (Scleractinia: Astrocoeniidae; Acroporidae). Coral Reefs 26, 231–239 (2007).
Waller, R. G. Deep-water Scleractinia (Cnidaria: Anthozoa): current knowledge of reproductive processesIn: Cold-water Corals and Ecosystems (Eds. Freiwald A. & Roberts J. M. ) 691–700 (Springer-Verlag: Berlin Heidelberg, 2005).
Waller, R. G. & Tyler, P. A. The reproductive biology of two deep-water, reef-building scleractinians from the NE Atlantic Ocean. Coral Reefs 24, 514–522 (2005).
Waller, R. G., Tyler, P. A. & Gage, J. D. Reproductive ecology of the deep-sea scleractinian coral Fungiacyathus marenzelleri (Vaughan, 1906) in the northeast Atlantic Ocean. Coral Reefs 21, 325–331 (2002).
Waller, R. G., Tyler, P. A. & Gage, J. D. Sexual reproduction in three hermaphroditic deep-sea Caryophyllia species (Anthozoa: Scleractinia) from the NE Atlantic Ocean. Coral Reefs 24, 594–602 (2005).
Willis, B. L., Babcock, R. C., Harrison, P. L. & Oliver, J. K. Patterns in the mass spawning of corals on the Great Barrier Reef from 1981 to 1984. Proc. 5th. Int. Coral Reef Symp 4, 343–348 (1985).
Wilson, J. R. & Harrison, P. L. Spawning patterns of scleractinian corals at the Solitary Islands-a high latitude coral community in eastern Australia. Marine Ecology Progress Series 260, 115–123 (2003).
Baird, A. H., Blakeway, D. R., Hurley, T. J. & Stoddart, J. A. Seasonality of coral reproduction in the Dampier Archipelago, northern Western Australia. Marine Biology 158, 275–285 (2011).
Baird, A. H., Cumbo, V. R., Figueiredo, J. & Harii, S. A pre-zygotic barrier to hybridization in two con-generic species of scleractinian corals. F1000Research 2, 193 (2013).
Fadlallah, Y. Reproduction in the coral Pocillopora verrucosa on the reefs adjacent to the industrial city of Yanbu (Red Sea, Saudi Arabia). Proceedings Of The 5th International Coral Reef Congress, Tahiti 4, 313–318 (1985).
Fadlallah, Y. H. Reproductive ecology of the coral Astrangia lajollaensis: Sexual and asexual patterns in a kelp forest habitat. Oecologia 55, 379–388 (1982).
Hirose, M., Kinzie, R. & Hidaka, M. Timing and process of entry of zooxanthellae into oocytes of hermatypic corals. Coral Reefs 20, 273–280 (2001).
Stoddart, J. a. & Black, R. Cycles of gametogenesis and plantation in the coral Pocillopora damicornis. Marine Ecology Progress Series 23, 153–164 (1985).
Wilson, J. R. & Harrison, P. L. Settlement-competency periods of larvae of three species of scleractinian corals. Marine Biology 131, 339–345 (1998).
Yonge, C. M. A Note on Balanophyllia regia, the only Eupsammiid Coral in the British Fauna. Journal of the Marine Biological Association of the United Kingdom 18, 219 (1932).
Barros, M. L. L., Pires, D. & Castro, C. B. Sexual reproduction of the Brazilian reef coral Siderastrea stellata Verrill 1868 (Anthozoa, Scleractinia). Bulletin of Marine Science 73, 713–724 (2003).
Bastidas, C., Croquer, A. & Bone, D. Shift of dominant species after a mass mortality on a Caribbean reef. Proceeding of the 10th International Coral Reef Symposium, Okinawa 1, 989–993 (2006).
Burgess, S. N. & Babcock, R. C. Reproductive ecology of three reef-forming, deep-sea corals in the New Zealand region. In Cold-Water Corals and Ecosystems (Eds. A. Freiwald, J. Roberts), pp. 701–713 (2005).
Harii, S., Omori, M., Yamakawa, H. & Koike, Y. Sexual reproduction and larval settlement of the zooxanthellate coral Alveopora japonica Eguchi at high latitudes. Coral Reefs 20, 19–23 (2001).
Harrison, P. L., Wallace, C. in Ecosystems of the world 25: Coral reefs. (ed. Dubinsky Z.) 133–207 (Elsevier, 1990).
Johnson, K. G. Synchronous planulation of Manicina areolata (Scleractinia) with lunar periodicity. Marine Ecology Progress Series 87, 265–273 (1992).
Lin, T. P. Reproduction patterns of scleractinian corals from Tung Ping Chau, Hong Kong and the effect of physical factors on these patterns, MPhil. Thesis The Chinese University of Hong Kong, (2003).
Loya, Y. The Red Sea coral Stylophora pistillata is an r strategist. Nature 259, 478–480 (1976).
Loya, Y., Sakai, K. & Heyward, A. Reproductive patterns of fungiid corals in Okinawa, Japan. Galaxea, Journal of Coral Reef Studies 11, 119–129 (2009).
Lueg, J. R., Moulding, A. L., Kosmynin, V. N. & Gilliam, D. S. Gametogenesis and Spawning of Solenastrea bournoni and Stephanocoenia intersepta in Southeast Florida, USA. Journal of Marine Biology 2012, 1–13 (2012).
Madsen, A., Madin, J. S., Tan, C. H. & Baird, A. H. The reproductive biology of the scleractinian coral Plesiastrea versipora in Sydney Harbour, Australia. Sexuality and Early Development in Aquatic Organisms 1, 25–33 (2014).
Penland, L., Kloulechad, J. & Idip, D. Timing of coral spawning in Palau. In: International Coral Reef Center, Palau, 12 (2004).
Peters, E. C. A survey of cellular reactions to environmental stress and disease in Caribbean scleractinian corals. Helgoländer Meeresuntersuchungen 37, 113–137 (1984).
Steiner, S. C. C. Comparative ultrastructural studies on scleractinian spermatozoa (Cnidaria, Anthozoa). Zoomorphology 113, 129–136 (1993).
Szmant, A. M. Sexual reproduction by the Caribbean reef corals Montastrea annularis and M. cavernosa. Marine Ecology Progress Series 74, 13–25 (1991).
Tanner, J. E. Seasonality and lunar periodicity in the reproduction of Pocilloporid corals. Coral Reefs 15, 59–66 (1996).
Vermeij, M. Evolutionary Ecology of the Coral genus Madracis on Caribbean Reefs. Ph.D. Thesis, University of Amsterdam (2002).
Wilson, J. R. Reproduction and larval ecology of broadcast spawning corals at the Solitary Islands, eastern Australia. Southern Cross University, (1998).
Yamazato, K., Sai, M. & Nakamura, M. Comparative studies on the reproductive mode among three genera of corals belonging to the family Pocilloporidae living in different geographical areas. Zoological Science 8, 1188 (1991).
Baird, A. H. & Babcock, R. C. Morphological differences among three species of newly settled pocilloporid coral recruits. Coral Reefs 19, 179–183 (2000).
Edmondson, C. H. Behavior of coral planulae under altered saline and thermal conditions. Bernice P Bishop Mus. Occ. Pap. 18, 283–304 (1946).
Graham, E. M., Baird, A. H. & Connolly, S. R. Survival dynamics of scleractinian coral larvae and implications for dispersal. Coral Reefs 27, 529–539 (2008).
Wyers, S. C. Sexual reproduction of the coral Diploria strigosa (Scleractinia, Faviidae) in Bermuda: research in progress. Proceedings Of The 5th International Coral Reef Congress, Tahiti 4, 301–306 (1985).
Wyers, S. C., Barnes, H. S. & Smith, S. R. Spawning of hermatypic corals in Bermuda: a pilot study. Hydrobiologia 216-217, 109–116 (1991).
Brown, B. E., Dunne, R. P., Ambarsari, I., Le Tissier, M. & Satapoomin, U. Seasonal fluctuations in environmental factors and variations in symbiotic algae and chlorophyll pigments in four Indo-Pacific coral species. Marine Ecology Progress Series 191, 53–69 (1999).
Coles, S. L. & Jokiel, P. L. Synergistic effects of temperature, salinity and light on the hermatypic coral Montipora verrucosa. Marine Biology 49, 187–195 (1978).
D’Croz, L. D., Mate, J. L. & Oke, J. E. Responses to elevated seawater temperature and UV radiation in the coral Porites lobata from upwelling and non-upwelling environments on the Pacific coast of Panama. Bulletin of Marine Science 69, 203–214 (2001).
Edmunds, P. J., Gates, R. D. & Gleason, D. F. The tissue composition of Montastrea franksi during a natural bleaching event in the Florida Keys. Coral Reefs 22, 54–62 (2003).
Fitt, W. K., Mc Farland, F. K., Warner, M. E. & Chilcoat, G. C. Seasonal patterns of tissue biomass and densities of symbiotic dinoflagellates in reef corals and relation to coral bleaching. Limnol. Oceanogr. 45, 677–685 (2000).
Fitt, W. K. & Warner, M. E. Bleaching Patterns of Four Species of Caribbean Reef Corals. Biological Bulletin 189, 298 (1995).
Glynn, P. W., Maté, J. L., Baker, A. C. & Calderón, M. O. Coral bleaching and mortality in panama and ecuador during the 1997–1998 El Niño–Southern Oscillation Event: spatial/temporal patterns and comparisons with the 1982–1983 event. Bulletin of Marine Science 69, 79–109 (2001).
Grottoli-Everett, A. G. & Kuffner, I. Uneven bleaching within colonies of the Hawaiian coral Montipora verrucosa. In: Ultraviolet Radiation and Coral Reefs (eds. Gulko, D. & Jokiel, P.) Hawaii Institute of Marine Biology Technical Report 41, 115–120 (1995).
Grottoli, A. G., Rodrigues, L. J. & Palardy, J. E. Heterotrophic plasticity and resilience in bleached corals. Nature 440, 1186–1189 (2006).
Harithsa, S., Raghukumar, C. & Dalal, S. G. Stress response of two coral species in the Kavaratti atoll of the Lakshadweep Archipelago, India. Coral Reefs 24, 463–474 (2005).
Le Tissier, M. & Brown, B. E. Dynamics of solar bleaching in the intertidal reef coral Goniastrea aspera at Ko Phuket, Thailand. Marine Ecology Progress Series 136, 235–244 (1996).
Ralph, P. J., Larkum, A. W. D. & Kühl, M. Photobiology of endolithic microorganisms in living coral skeletons: 1. Pigmentation, spectral reflectance and variable chlorophyll fluorescence analysis of endoliths in the massive corals Cyphastrea serailia, Porites lutea and Goniastrea australensis. Marine Biology 152, 395–404 (2007).
Saxby, T., Dennison, W. C. & Hoegh Guldberg, O. Photosynthetic responses of the coral Montipora digitata to cold temperature stress. Marine Ecology Progress Series 248, 85–97 (2003).
Szmant, A. M. & Gassman, N. J. The effects of prolonged? bleaching? on the tissue biomass and reproduction of the reef coral Montastrea annularis. Coral Reefs 8, 217–224 (1990).
Venn, A. A., Wilson, M. A., Trapido Rosenthal, H. G., Keely, B. J. & Douglas, A. E. The impact of coral bleaching on the pigment profile of the symbiotic alga, Symbiodinium. Plant, Cell and Environment 29, 2133–2142 (2006).
Warner, M. E., Fitt, W. K. & Schmidt, G. W. The effects of elevated temperature on the photosynthetic efficiency of zooxanthellae in hospite from four different species of reef coral: a novel approach. Plant, Cell and Environment 19, 291–299 (1996).
Achituv, Y., Ben-Zion, M. & Mizrahi, L. Carbohydrate, lipid, and protein composition of zooxanthellae and animal fractions of the coral Pocillopora damicornis exposed to ammonium enrichment. Pacific Science 48, 224–233 (1994).
Lovelock, C. E., Reef, R. & Pandolfi, J. M. Variation in elemental stoichiometry and RNA:DNA in four phyla of benthic organisms from coral reefs. Functional Ecology 28, 1299–1309 (2014).
Anthony, K. R. N., Connolly, S. R. & Willis, B. L. Comparative analysis of energy allocation to tissue and skeletal growth in corals. Limnol. Oceanogr. 47, 1417–1429 (2002).
Hoegh Guldberg, O. & Salvat, B. Periodic mass-bleaching and elevated sea temperatures: bleaching of outer reef slope communities in Moorea, French Polynesia. Marine Ecology Progress Series 121, 181–190 (1995).
Data Citations
Madin, J. S. The Coral Trait Database https://coraltraits.org/releases/ctdb_1.1.1.zip (2016)
Madin, J. S. Figshare http://dx.doi.org/10.6084/m9.figshare.2067414 (2016)
Acknowledgements
The authors would like to thank Macquarie University’s Genes to Geoscience Research Centre for supporting the Coral Trait Working group. In particular, we would like to thank Mark Westoby, Mariella Herberstein and Sam Newton. J.S.M. was supported by an Australian Research Council Future Fellowship. S.A.K. and M.H.A. were supported by the Danish National Research Foundation. C.E.L. and J.M.P. were supported by an Australian Research Council Discovery Project (DP0986179). T.B., S.R.C., M.O.H., C.-Y.K., J.M.P., M.S.P., T.E.R. and A.H.B. were supported by the ARC Centre of Excellence for Coral Reef Studies.
Author information
Authors and Affiliations
Contributions
J.S.M. and A.H.B. conceived the idea. J.S.M., M.D. and A.H.B. compiled the preliminary data. J.S.M., K.D.A., A.H.A., T.B., S.D.C., S.C., S.R.C., E.D., M.D., D.F., E.C.F., R.D.G., A.M.T.H, M.O.H., D.H., S.A.K., M.A.K., C.K., J.M.L., C.E.L., O.L., J.M., T.M., J.M.P., X.P., M.S.P., H.M.P., T.E.R., M.S., C.C.W., E.W. and A.H.B. compiled, entered and edited trait data and jointly wrote the data descriptor.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing financial interest.
ISA-Tab metadata
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0 Metadata associated with this Data Descriptor is available at http://www.nature.com/sdata/ and is released under the CC0 waiver to maximize reuse.
About this article

Cite this article
Madin, J., Anderson, K., Andreasen, M. et al. The Coral Trait Database, a curated database of trait information for coral species from the global oceans. Sci Data 3, 160017 (2016). https://doi.org/10.1038/sdata.2016.17
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/sdata.2016.17
This article is cited by
-
Global disruption of coral broadcast spawning associated with artificial light at night
Nature Communications (2023)
-
Prediction of habitat complexity using a trait-based approach on coral reefs in Guam
Scientific Reports (2023)
-
Co-variation of fish and coral traits in relation to habitat type and fishery status
Coral Reefs (2023)
-
A test of adaptive strategy theory using fifteen years of change in coral abundance
Coral Reefs (2023)
-
Predictive models for the selection of thermally tolerant corals based on offspring survival
Nature Communications (2022)
