Article Text

Abstract
Objectives Survival machine learning (ML) has been suggested as a useful approach for forecasting future events, but a growing concern exists that ML models have the potential to cause racial disparities through the data used to train them. This study aims to develop race/ethnicity-specific survival ML models for Hispanic and black women diagnosed with breast cancer to examine whether race/ethnicity-specific ML models outperform the general models trained with all races/ethnicity data.
Methods We used the data from the US National Cancer Institute’s Surveillance, Epidemiology and End Results programme registries. We developed the Hispanic-specific and black-specific models and compared them with the general model using the Cox proportional-hazards model, Gradient Boost Tree, survival tree and survival support vector machine.
Results A total of 322 348 female patients who had breast cancer diagnoses between 1 January 2000 and 31 December 2017 were identified. The race/ethnicity-specific models for Hispanic and black women consistently outperformed the general model when predicting the outcomes of specific race/ethnicity.
Discussion Accurately predicting the survival outcome of a patient is critical in determining treatment options and providing appropriate cancer care. The high-performing models developed in this study can contribute to providing individualised oncology care and improving the survival outcome of black and Hispanic women.
Conclusion Predicting the individualised survival outcome of breast cancer can provide the evidence necessary for determining treatment options and high-quality, patient-centred cancer care delivery for under-represented populations. Also, the race/ethnicity-specific ML models can mitigate representation bias and contribute to addressing health disparities.
- machine learning
- artificial intelligence
- health equity
- informatics
Data availability statement
Data may be obtained from a third party and are not publicly available. We used the National Cancer Institute's Surveillance, Epidemiology and End Results (SEER) Program data. It provides information on cancer statistics in an effort to reduce the cancer burden among the US population.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
WHAT IS ALREADY KNOWN ON THIS TOPIC
Survival machine learning allows healthcare professionals to identify patients at high risk, but models trained with data poorly representative of minority groups, they may exacerbate health disparities. To date, no study developed race/ethnicity-specific survival machine learning models for Hispanic and black women diagnosed with breast cancer.
WHAT THIS STUDY ADDS
The race/ethnicity-specific survival machine learning models outperformed the general models trained with all races/ethnicity when predicting the outcomes of specific races/ethnicity.
HOW THIS STUDY MIGHT AFFECT RESEARCH, PRACTICE OR POLICY
Predicting the individualised survival outcome of breast cancer can provide the evidence necessary for determining treatment options and high-quality, patient-centred cancer care delivery for underrepresented populations. Also, the race/ethnicity-specific machine learning models can mitigate representation bias and contribute to addressing health disparities.
Introduction
Breast cancer is the second-leading cause of cancer-related deaths in women in the USA, and it affects every ethnic group of women in the USA.1 2 However, there are racial and ethnic divides in cancer survival. Breast cancer is the most prevalent reason for cancer-related death in Hispanic women in the USA.3 Also, minority women, especially black women, have a higher mortality rate (26.8 per 100 000 women) even though white women (18.8 per 1 00 000 women) have higher cancer incidence.2 4 5 These facts indicate that the cancer survival rates need to be improved among Hispanic and black women, and various features contributing to breast cancer mortality should be understood to provide tailored intervention for enhanced survival.
Unlike traditional survival models that use a standard statistical method, survival machine learning (ML) has been suggested as a useful approach for learning the patterns from high-dimensional data and complex feature interactions for forecasting future events.6 This approach allows healthcare professionals to identify patients at high risk or predict those who need increased utilisation of healthcare services to proactively support and provide interventions necessary for the patients.7 However, a growing concern exists that ML models have the potential to cause racial disparities through the data used to train them.8 The ML model trained with the data representing general population would not contain sufficient number of participants from the minority population and is biased, resulting in inaccurate predictions for the minority group even if the overall accuracy is high.9 If the ML models trained with data poorly representative of minority groups are used in healthcare, they may exacerbate health disparities.10 To address such harmful effects, it is recommended to train an ML model with data that resemble the population that the model is intended to use.11 12 To the best of our knowledge, no study developed race/ethnicity-specific survival ML models for Hispanic and black women diagnosed with breast cancer.
Therefore, there is a need for race/ethnicity-specific survival ML models trained with the underrepresented populations to examine the feasibility of race/ethnicity-specific ML models that may outperform the general model trained with all races/ethnicity. Accurate prediction of the individualised outcome will enable tailored healthcare delivery and a better outcome for the underrepresented populations. This study aims to develop race/ethnicity-specific survival ML models for Hispanic and black women diagnosed with breast cancer to examine whether race/ethnicity-specific ML models outperform the models trained with the general population data when predicting the survival of Hispanic and black women diagnosed with breast cancer.
Methods
Data source
We used the data from the US National Cancer Institute’s population-based Surveillance, Epidemiology and End Results (SEER) programme registries. The SEER programme currently collects and publishes cancer incidence and survival data in the USA from population-based cancer registries in 22 geographical areas, representing approximately 48% of the US population.13 The SEER data are considered the gold standard for data quality among cancer registries in the USA and globally.14 We selected adult female patients’ data (18 or older) from SEER who had breast cancer diagnoses between 1 January 2000 and 31 December 2017. Also, we selected California as the geographical location for the diverse characteristics of the patient population. The Hispanic population included all races, and the black population was non-Hispanic. Figure 1 shows the flow chart of data collection.
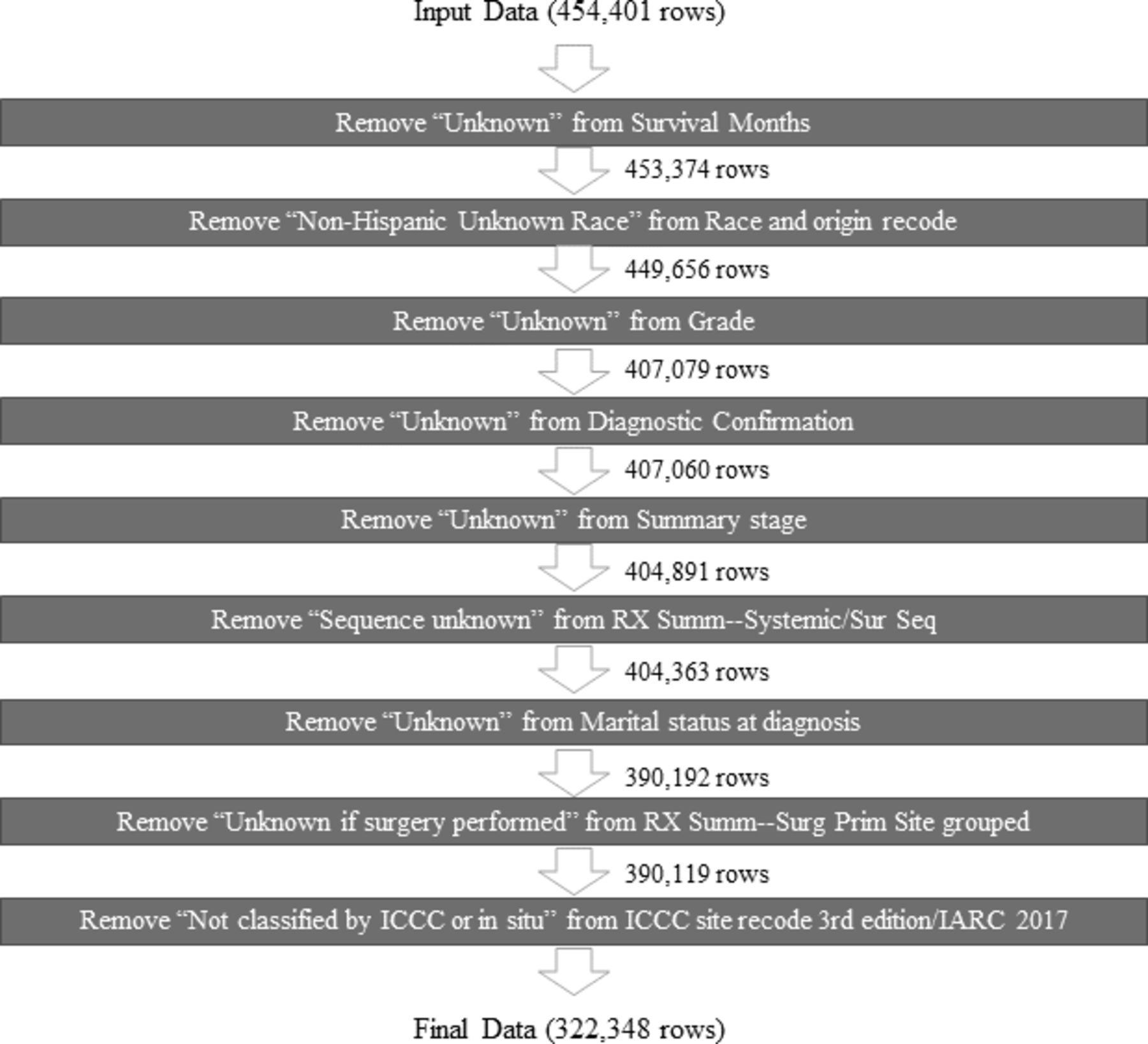
Flow chart of data collection.
Predictor and outcome variables
The predictor variables included age at cancer diagnosis, marital status at diagnosis, first malignant primary tumour indicator, the sequence number of tumours, primary site, histology, the total number of in situ/malignant tumours, SEER summary stage, derived stage, grade, regional lymph nodes examined, regional lymph nodes positive, oestrogen receptor status, progesterone receptor status, chemotherapy, radiation, sequence of radiation and surgery performed, reason no cancer-directed surgery and sequence of systemic therapy and surgical procedures. Vital status was recorded as alive/dead at the time of the cut-off date (31 December 2017). The sequence number of tumours describes the sequence of all reportable tumours that occurred over a patient’s lifetime.
The outcome variable was the survival months of a patient.
Data preprocessing and preparation
Before training the survival models, we preprocessed the predictor variables to enhance the ML modelling performance. Rows containing missing values were dropped. All the categorical features were reencoded using a one-hot-encoding scheme where each new column represented a single category. We applied variance filtering (with the threshold of 0.01) to drop the features that were near-constant or had low variance. Thus, a feature containing outliers would appear as a low-variance column and be filtered out. Once the preprocessing was completed, the final dataset was exported into a new flat file for the training. To train an ML model for survival analysis, the ‘survival months’ variable was used as the target for the training. ‘Vital status’ was used for the event.
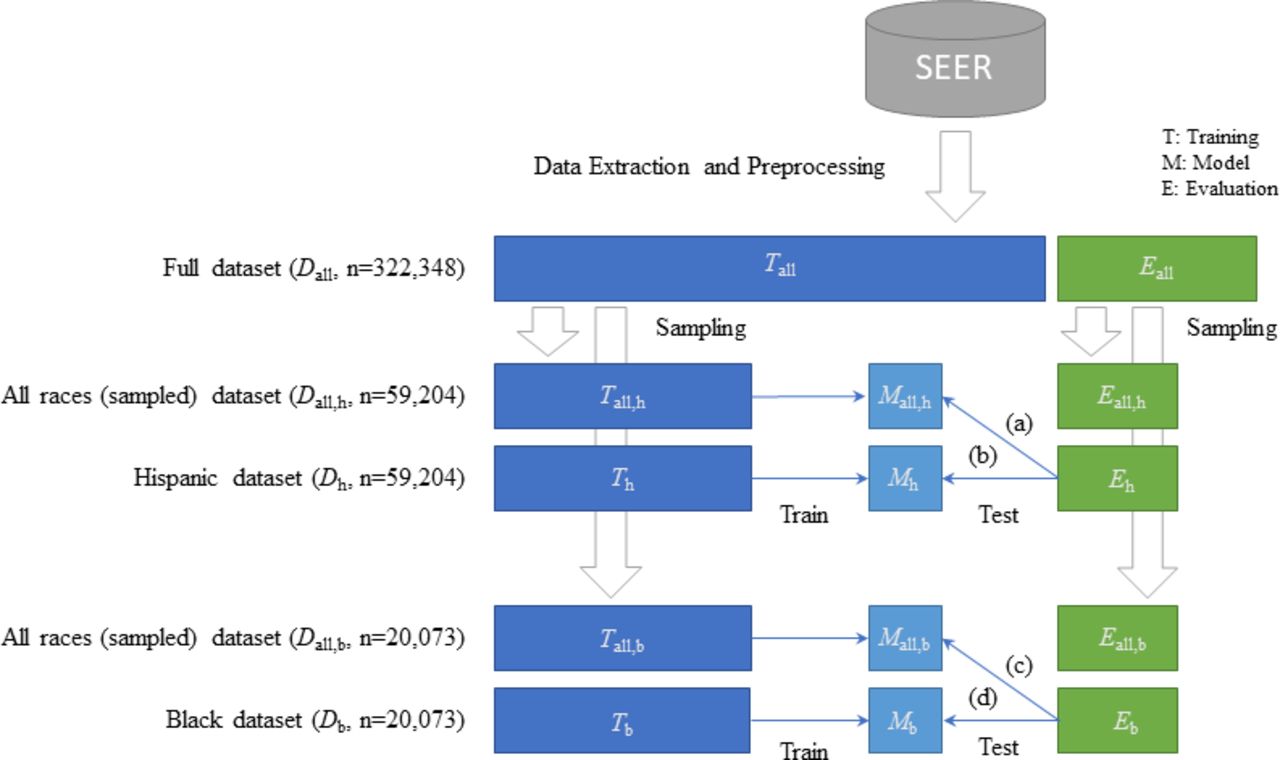
We took several steps for data preparation to develop race/ethnicity-specific models for the Hispanic and black populations and compare them with the general model that included all races/ethnicity. Figure 2 shows the process of data preparation for model development.

Data preparation for model development. SEER, Surveillance, Epidemiology and End Results.
First, we split the full dataset into a training set (Tall) for model development and a test set (Eall) for evaluation with a 7:3 ratio to randomly sample the populations. Each set was used to sample the populations for model development randomly. The randomly sampled population sets maintained the original ratio of each race/ethnicity in the full dataset. Second, we extracted the Hispanic population from the original training set, Tall (Th) to train the Hispanic-specific model (Mh). We also extracted the Hispanic population from the original test set, Eall (Eh) to test the model, Mh. Then, we randomly sampled the populations from the original training set (Tall) that included all races/ethnicity (Tall,h), to match the exact number of samples used for the Hispanic-specific model training. We also randomly sampled the populations from the original test set (Eall) that included all races/ethnicity (Eall,h), to match the exact number of samples used for the Hispanic-specific model testing. Tall,h was used to develop a model Mall,h. Then, the performance of the models Mall,h (a) and Mh (b) were compared with the same test set, Eh. Third, we repeated the process of Hispanic-specific model development for Black-specific model development.
We extracted the black population from the original training set, Tall (Tb) to train the black-specific model (Mb). We also extracted the black population from the original test set, Eall (Eb) to test the model, Mb. Then, we randomly sampled the populations from the original training set (Tall) that included all races/ethnicity (Tall,b), to match the exact number of samples used for the black-specific model training. We also randomly sampled the populations from the original test set (Eall) that included all races/ethnicity (Eall,b), to match the exact number of samples used for the black-specific model testing. Tall,b was used to develop a model Mall,b. Then, the performance of the models Mall,b (c) and Mb (d) were compared with the same test set, Eb.
Race/ethnicity-specific models
For the survival ML modelling, we developed and compared four models: Cox proportional-hazards (PH) model (CoxPH), Gradient Boost Tree (GBT), survival tree (ST) and survival support cector machine (SSVM). The description of each model is shown in table 1.
Description of survival machine learning models
Each model’s performance was evaluated using the C-index. The C-index is a standard way of measuring the performance of survival models. It can be viewed as the fraction of all pairs of patients predicted to have correct orders over the total number of possible evaluation pairs.15
For each race/ethnicity, we trained and compared two different models based on the two datasets mentioned above—one with a specific race/ethnicity and the other one with all races/ethnicity. Our hypothesis was that the model trained with specific race/ethnicity would outperform the general model trained with all races/ethnicity when predicting the breast cancer survival of a specific race/ethnicity.
Results
Sample characteristics
A total of 322 348 female patients who had breast cancer diagnoses between 1 January 2000 and 31 December 2017 were identified. Among them, the number of Hispanic patients was 59 204 (18.4%), and black was 20 073 (6.2%). Table 2 shows the detailed characteristics of the study sample, Hispanic, black and all races/ethnicity.
Sample characteristics
Compared with all races/ethnicity (15.2%) and Hispanic (14.9%) populations, more black population was dead (24.4%). Hispanic population’s survival months (mean: 80.6, median: 67.0) were lower compared with all races/ethnicity (90.4, 79.0) and black (82.9, 69.0) populations. Hispanic population was younger (mean:55.3, median 54.0), compared with all races/ethnicity (59.1, 59.0) and black (57.8, 57.0) populations. Black (36.6%) and Hispanic (39.2%) population had higher percentage of poorly differentiated grade III cancer, compared with all races/ethnic (32.7%) groups. Black population had lower percentages of positive oestrogen receptor status (65.6%), compared with all races/ethnicity (77.4%) and Hispanic (73.5%) populations. Also, black population had lower percentages of positive progesterone receptor status (52.1%), compared with all races/ethnicity (65.6%) and Hispanic (62.3%) populations.
Lower percentages of Hispanic (51.0%) and black (50.0%) populations had chemotherapy compared with all races/ethnicity (57.4%). Higher percentages of black (57.3%) and Hispanic (55.6%) populations had no radiation and/or cancer-directed surgery, compared with all races/ethnicity (52.3%). Higher percentages of overall (46.4%) and Hispanic (43.4%) populations had radiation after surgery than Black (41.5%) populations.
Figure 3 shows the Kaplan-Meier curves of the Hispanic, black and all races/ethnic groups. All races/ethnic groups had the better survival than the Hispanic and black groups.

Kalplan-Meier survival curves.
Data preprocessing and preparation
After data preprocessing and cleaning, the final dataset for analysis contained 260 variables. Values in ‘Derived stages’ variable were grouped into ‘0’, ‘I’, ‘II’, ‘III’, ‘IV’ and ‘unknown’. ‘Regional nodes examined’ and ‘Regional nodes positive’ were integer variables which contains both numeric and encoded values (90+). Numeric values were categorised (ie, 0–9, 11–19, …, 40+), while encoded values were mapped to ‘oher’.
Model development
We extracted 59 204 Hispanic populations for each training set for Hispanic-specific model (Th) and a comparison model with all races/ethnicity (Tall,h). Also, we extracted 20 073 black populations for each training set for black-specific model (Tb) and a comparison model with all races/ethnicity (Tall,b). Once data were prepared, we applied variance filtering and dropped the features that had low variance. After filtering, the number of features we had for the Th was 72, and for the Tall,h was 71 for Hispanic-specific model training, and the number of features we had for the Tb and Tall,b was 72 for the black-specific model training.
During the training, both training sets (race-specific and all races/ethnicity) were further split into actual training set and validation set during a cross-validation phase when parameter tuning was necessary (GBT and ST models). We used random search method to find the most optimal parameters for each survival analysis model. We used 20 iterations and 5-fold cross validation was used for all cases for each training. We used scikit-survival package (V.0.17.1) for the modelling (CoxPHSurvivalAnalysis class for CoxPH, Gradient Boosting Survival Analysis class for GBT, SurvivalTree class for ST and FastKernelSurvivalSVM class for SSVM), scikit-learn (V.1.0.2) for the feature selection (VarianceThreshold), hyperopt (V.0.2.7) for the hyperparameter search, and pandas (V.1.4.1) for general data preprocessing and preparation.
Model evaluations
The model evaluation results are shown in table 3 and figure 4 where we compared different combinations of modelling methods and input training/test sets.
Model performance comparison using c-index

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Race/ethnicity-specific model performance comparison using C-index. GBT, Gradient Boost Tree; PH, proportional hazards; SSVM, survival support vector machine; ST, survival tree.
Hispanic-specific model (Mh) and all races/ethnicity model (Mall,h) were evaluated using the same the test set (Eh). Hispanic-specific model (Mh) outperformed all races/ethnicity model (Mall, h) in three out of four approaches, which were Cox PH (0.832 vs 0.828), ST (0.772 vs 0.763) and SSVM (0.834 vs 0.790). The GBT model showed the same c-index score (0.813) for both models.
Black-specific model (Mb) and all races/ethnicity model (Mall,b) were evaluated using the same the test set (Eb). Black-specific model (Mb) outperformed all races/ethnicity model (Mall,b) in all four approaches, Cox PH (0.823 vs 0.821), GBT (0.808 vs 0.803), ST (0.804 vs 0.801) and SSVM (0.824 vs 0.786). In both race/ethnicity-specific models, Cox PH showed the highest c-index score followed by GBT, SSVM and ST.
Discussion
Accurately predicting the survival outcome of a patient is critical in determining treatment options and providing appropriate cancer care. The ML approaches provide a robust way of predicting health outcomes using large data points with complex feature interactions. However, current ML models are often built with all races/ethnicity data, having the potential to have representation bias, and not tailored to each minority group. To date, race/ethnicity-specific survival ML models predicting the outcomes of the black and Hispanic women diagnosed with breast cancer are lacking. This study developed and evaluated race/ethnicity-specific survival ML models for black and Hispanic women with breast cancer and compared with the general population model. The high performing ML models developed in this study will be able to contribute to providing individualised oncology care and improving the survival outcome of specific populations, the black and Hispanic women. Also, it is a strength of our model that we used the patient data from more than 3 22 348 women in a large, population-based dataset from 2000 to 2017, including 59 204 (18.4%) Hispanic women and 20 073 (6.2%) Black women.
The sample population in this study showed that the black population had the highest death rate followed by the Hispanic and all races/ethnicity, supporting the findings from other literature.4 5 Also, the survival months for the black and Hispanic groups were low and they were younger compared with all races/ethnicity. It is congruent with the literature that young black women have higher breast cancer mortality than young white women,16 17 and the Latinas have the higher rates of more advanced cancer than non-Hispanic Whites.18 Also, breast cancer is more aggressive in younger women than older premenopausal women.19 Our study sample also showed that the Hispanic and black populations had higher percentage of poorly differentiated grade III cancer than overall populations. Poorly differentiated tumours lack normal features, tend to grow and spread faster and have a worse prognosis20; and these tumours expressed lower levels of oestrogen receptor.21 Our study sample showed likewise that Hispanic and black populations showed the lower percentage of oestrogen receptor positive status and progesterone receptor positive status than overall population. Studies have shown that young age breast cancer has more advanced stage at presentation, more grades and higher oestrogen receptor negativity.22
The result also showed that lower percentages of Hispanic and black populations had chemotherapy. Existing literature has shown that African American and Hispanic patients tend to experience diagnostic and treatment delays, which were related to worse survival outcomes.23 24 Perhaps lower percentages of Hispanic and black patients receiving chemotherapy were associated with the fewer survival months of the Hispanic and black populations in this study.
After the race/ethnicity-specific model development and evaluation, we observed that the general models trained with all races/ethnicity did not perform well when tested with specific races/ethnicity. That is, the race/ethnicity-specific survival ML models developed in this study consistently outperformed the general models when predicting the outcomes of specific race/ethnicity, addressing bias in ML. Especially, black and Hispanic-specific survival ML models using the Cox PH approach showed the best performance among the four ML models tested, showing that this model outperformed the other models in predicting the survival of specific race/ethnicity. Also, the ST model performance showed the highest difference between the race/ethnicity-specific model and the general model. This indicates that the ST model tends to overfit to a specific race/ethnicity compared with the other models. Our study demonstrated that a tailored ML model for each race/ethnicity is needed to better predict the patient survival than the general ML model using all races/ethnicity. By accurately forecasting a patient’s survival, healthcare professionals will be able to guide individualised treatment decisions and provide tailored interventions for the well-being of a cancer survivor.
It is worth noting that although the performance of the general model is not low, it was trained with the general population with an imbalanced portion of the underrepresented population, including the Hispanic and black populations. It was still meaningful to examine the feasibility of race/ethnicity-specific models since it is recommended to train an ML model with data resembling the people the model is intended to use to mitigate representation bias. Although the performance difference between the models was sometimes marginal depending on the algorithms, our race/ethnicity-specific models consistently outperformed the general model. It shows the potential to accurately predict individualised patient outcomes for quality care delivery for underrepresented populations and lead to alleviating health disparities.
There are several limitations to this study. The SEER database only includes the first course of treatment and do not have information on adjuvant therapy.25 This causes difficulties comparing the outcomes of the treatment sequence. To overcome this limitation, a comprehensive database that has more information on cancer treatment can be used as a future work to provide additional insights on the impact of treatment sequence. Also, the dataset did not include the human epidermal growth factor 2 receptor status, which is a critical tumour marker for breast cancer prognosis. The variable was missing because it was collected from 2010, but our data were dated from 2000. Incorporating this variable in the modelling will be needed in future work to provide more accurate predictions for patient outcomes.
Conclusion
This study has developed and evaluated accurate race/ethnicity-specific survival ML models for black and Hispanic women diagnosed with breast cancer. Predicting the individualised survival outcome of breast cancer can provide the evidence necessary for determining treatment options and high-quality, patient-centred cancer care delivery for underrepresented populations. Also, the race/ethnicity-specific ML models can mitigate representation bias and contribute to addressing health disparities.
Data availability statement
Data may be obtained from a third party and are not publicly available. We used the National Cancer Institute's Surveillance, Epidemiology and End Results (SEER) Program data. It provides information on cancer statistics in an effort to reduce the cancer burden among the US population.
Ethics statements
Patient consent for publication
Ethics approval
Since the data were fully deidentified, this study was not considered human subject research by the Institutional Review Board at the University, and no informed consent was required.
References
Footnotes
Contributors All the authors contributed to the design of the work and the final approval of the submission. JIP worked on the data acquisition, analysis and interpretation of the data, and acted as guarantor. SB contributed to the data analysis. JWP and SL contributed to the interpretation of data for the work.
Funding The authors have not declared a specific grant for this research from any funding agency in the public, commercial or not-for-profit sectors.
Competing interests None declared.
Provenance and peer review Not commissioned; externally peer reviewed.