Article Text

Abstract
Objectives Early diagnosis and intervention are keys for improving long-term outcomes of children with autism spectrum disorder (ASD). However, existing screening tools have shown insufficient accuracy. Our objective is to predict the risk of ASD in young children between 18 months and 30 months based on their medical histories using real-world health claims data.
Methods Using the MarketScan Health Claims Database 2005–2016, we identified 12 743 children with ASD and a random sample of 25 833 children without ASD as our study cohort. We developed logistic regression (LR) with least absolute shrinkage and selection operator and random forest (RF) models for predicting ASD diagnosis at ages of 18–30 months, using demographics, medical diagnoses and healthcare service procedures extracted from individual’s medical claims during early years postbirth as predictor variables.
Results For predicting ASD diagnosis at age of 24 months, the LR and RF models achieved the area under the receiver operating characteristic curve (AUROC) of 0.758 and 0.775, respectively. Prediction accuracy further increased with age. With predictor variables separated by outpatient and inpatient visits, the RF model for prediction at age of 24 months achieved an AUROC of 0.834, with 96.4% specificity and 20.5% positive predictive value at 40% sensitivity, representing a promising improvement over the existing screening tool in practice.
Conclusions Our study demonstrates the feasibility of using machine learning models and health claims data to identify children with ASD at a very young age. It is deemed a promising approach for monitoring ASD risk in the general children population and early detection of high-risk children for targeted screening.
- Electronic Health Records
- Machine Learning
- Medical Informatics
- Outcome Assessment, Health Care
Data availability statement
Data may be obtained from a third party and are not publicly available.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
WHAT IS ALREADY KNOWN ON THIS TOPIC
Growing evidence has shown that existing autism spectrum disorder (ASD)-specific screening tools (eg, Modified Checklist for Autism in Toddlers) may not yield sufficient accuracy for early detection of children with ASD in clinical practice.
Previous clinical and health service research has identified clinical risk factors associated with ASD, but the clinical factors from an individual’s prior medical history have not been used comprehensively to assess the risk of ASD in young children.
WHAT THIS STUDY ADDS
This study demonstrated the feasibility of predicting ASD diagnosis with promising accuracy based on an individual’s medical record from health claims data using machine learning models.
Our prediction models were clinically interpretable, which systematically identified key predictors in line with known risk factors and symptoms among ASD children in the literature.
HOW THIS STUDY MIGHT AFFECT RESEARCH, PRACTICE OR POLICY
This study may serve as a basis for integrating predictive modelling into the health information system and the clinical workflow to enhance the current ASD screening practice.
Introduction
Autism spectrum disorder (ASD) is a developmental disorder that involves persistent challenges in social interaction, speech and nonverbal communication, and restricted and repetitive behaviours.1 In the USA, the prevalence of ASD has increased substantially in the past two decades, with an estimate of every 1 in 44 children to be identified with ASD by age 8 in 2016.2 Although there exist evidence-based interventions which improve core symptoms in children with ASD, many children with ASD still experience long-term challenges with daily life, education and employment.3
Early diagnosis is the key to early intervention for improving the long-term outcomes of children with ASD. However, despite the growing evidence shows that accurate and stable diagnoses can be made by 2 years,4 in real-world settings, the median age of ASD diagnosis is 50 months.2 To improve early diagnosis, the American Academy of Pediatrics (AAP) has recommended universal screening among all children at 18-month and 24-month well-child visits in the primary care settings using the Modified Checklist for Autism in Toddlers (M-CHAT),5 a questionnaire that assesses children’s behaviour for toddlers.6 However, growing evidence has shown that using M-CHAT alone may not yield sufficient accuracy in detecting ASD cases, with a sensitivity below 40% and a positive predictive value (PPV) under 20%.7 8
In addition to ASD-specific behavioural questionnaires, general clinical and healthcare records may also contain meaningful signals to differentiate the ASD risks among very young children. Studies have found that children with ASD are oftentimes accompanied by certain symptoms and medical issues such as gastrointestinal problems,9 infections10 11 and feeding problems.12 This implies that past diagnosis and healthcare encounter information, commonly available from health insurance claims or Electronic Healthcare Record (EHR), could potentially be used for ASD risk prediction. In fact, medical claims and EHR data have been widely used in the health informatics literature for identifying disease-specific early phenotypes even before the hallmark symptoms start to manifest, such as for chronic diseases like heart failures,13 diabetes14 and Alzheimer’s disease.15 In the context of ASD, health record data has been used to identify the ASD subtypes16 17 and to predict the suicidal risk in adolescents with ASD18; however, its use for predicting ASD diagnosis in young children has remained limited. To fill this gap, the objective of this study is to examine the feasibility of using large-scale real-world medical claims data to develop a prediction model for ASD diagnosis in young children, which can be used to support effective ASD screening strategies and facilitate early detection.
Methods
Data source
We used the deidentified individual-level longitudinal healthcare claims data from the IBM MarketScan Commercial Claims and Encounters Database from 2005 to 2016. This database includes over 273 million unique individuals for both privately and publicly insured people in the USA.19 The claims data include baseline demographics (eg, sex, birth year, postal region), service providers, insurance plans, medical diagnoses (in international Classification of Diseases (ICD)-9/10 codes) and procedures (in Healthcare Common Procedure Coding System (HCPCS) and Current Procedural Terminology-4 codes) at each encounter of healthcare services.
Study population
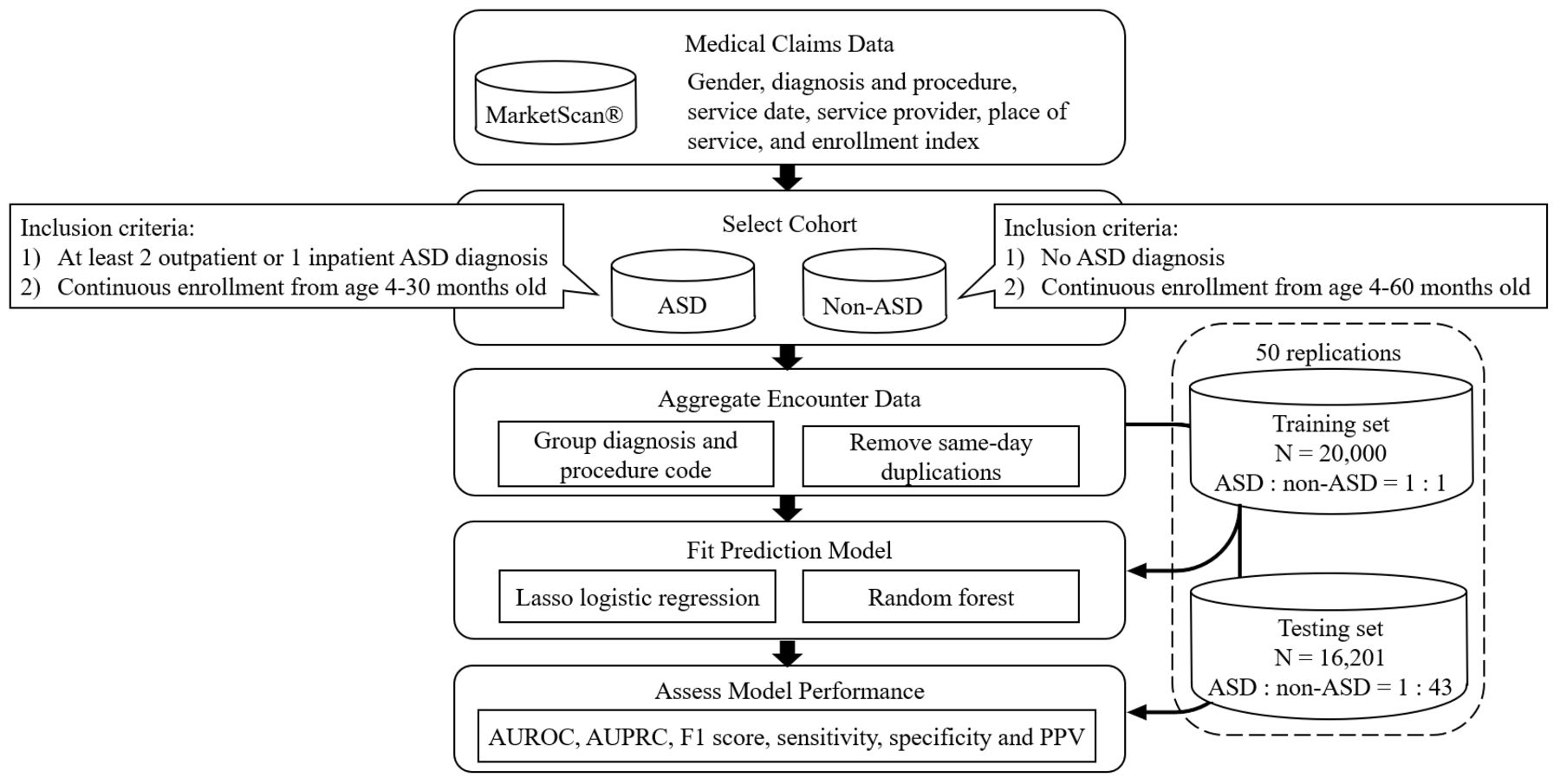
We constructed an initial cohort consisting of young children with and without ASD (figure 1). The inclusion criteria of the ASD cohort are as follows: (1) having at least 2 outpatient or 1 inpatient ASD diagnosis encounters (299 for ICD-9 and F84 for ICD-10) throughout the existing records20 21; and (2) having continuous enrolment from 4 months to 30 months to ensure the completeness of health records from the claims data that can be used for diagnosis prediction at up to 30 months (online supplemental figure S1). To create the non-ASD cohort, we first identified individuals without any ASD diagnosis throughout their health records, then downsampled 5% of the population to obtain a computationally manageable yet sufficiently large subset of samples. To ensure patients had adequate follow-up time to receive confirmed ASD diagnosis in the database, we restricted our selection of non-ASD patients by requiring a full enrolment period from 4 months to 60 months (online supplemental table S1).
Supplemental material

Overview of study design for the predictive analysis. ASD, autism spectrum disorder; AUROC, area under receiver operating characteristic curve; AUPRC, area under precision-recall curve; LASSO, least absolute shrinkage and selection operator; PPV, positive predictive value.
Predictor variables for ASD diagnosis
We examined all diagnosis and procedure codes of a child’s medical encounters available from as early as within 4 months after birth up to the age for prediction of ASD. We applied the Clinical Classifications Software (CCS),22 a commonly used tool in health informatics research, to aggregate the large number of distinct diagnosis and procedure codes into clinically meaningful groups (figure 1). The single-level CCS maps the ICD-9/10 and HCPCS codes to a substantially smaller yet practical set that includes 285 diagnosis and 231 procedure categories.22 We further removed the same-day duplications of CCS codes after the mapping by counting at most one encounter of a specific CCS category for each person on each day.
To predict the ASD diagnosis at the age of 24 months in our base case model, in line with the age when a diagnosis can possibly be made by an experienced professional,4 we defined the predictor variables as the total number of encounters for each CCS category up to the age for prediction of 24 months. We also included sex and the encounters of emergency department visits, which are well-known clinically relevant factors associated with the autism population.23 Variables that were present in <1% of both ASD and non-ASD cohorts were excluded.24 A total of 170 input predictor variables were included for prediction at the age of 24 months. Having considered that the course of clinical events may be following a different pattern after an encounter with ASD diagnosis, we excluded any children who had at least one encounter with ASD diagnosis code prior to the age for prediction in our analysis.
Prediction model development and validation
We employed two machine learning methods, logistic regression (LR) and random forest (RF), which have been widely used for developing risk prediction models in various clinical settings. LR assumes that the independent variables are linearly related to the log odds and that the effects of multiple variables are additive, whereas RF is particularly suitable for exploiting nonlinear interactive effects in high-dimensional data. For the LR model, we also applied the least absolute shrinkage and selection operator (LASSO) as a feature selection technique to enforce the coefficients of weak predictors to be zero. The RF model was limited to up to 100 decision trees in the base case setting (other choices of the maximum number of trees were tested in sensitivity analysis).
To train our model, we sampled 10 000 ASD and 10 000 non-ASD subjects (N=20 000) from the initial cohort to build a large balanced training sample for maximising the discriminatory power learnt by the prediction model. To evaluate the model prediction performance, we created an independent imbalanced testing set (N=16 201) comprised of ASD and non-ASD patients from the remaining cohort that were mutually exclusive from the training set. The testing set resembled the real-world estimates for ASD prevalence of 2.3% (ie, 1 in every 44) in the general population.2
We measured the prediction performance with sensitivity (also known as true positive rate or recall), specificity (or true negative rate) and PPV (or precision)25 at various selected risk thresholds. The model’s overall discrimination ability was measured using the area under the receiver operating characteristic curve (AUROC). We also calculated the area under the precision-recall curve (AUPRC) where the precision-recall curve represents the relationship between PPV and sensitivity, and F1 score is defined as the harmonic mean of PPV and sensitivity, which are suited for evaluating the prediction performance for the imbalanced testing sample.26 27 To assess the stability and the uncertainty of prediction performance, we repeated the training and testing set sampling, model training, testing and performance evaluation with 50 independent replications. The 95% CIs of all performance measures were reported.
Predicting ASD diagnosis at different ages
In addition to the base case prediction model where the risk of ASD diagnosis was assessed based on clinical information up to 24 months, we compared the accuracy of ASD prediction with varying lengths of available medical history at (1) a younger age, 18 months, considering that the universal ASD screening is recommended for children at both 18 months and 24 months5; and (2) an older age, 30 months, which is still a critical time point for monitoring the developmental delays and consideration of early intervention.28 We followed the same approach in the base case to exclude predictor variables of low frequency (resulting in 150 and 180 predictor variables in total for prediction at 18 and 30 months, respectively) and the children with ASD diagnosis prior to the age for prediction.
Identifying key predictor variables
We further explored how many and which key predictive variables had the most impact on the prediction performance using the Gini importance index from the RF model. We added variables incrementally following the order of Gini Index (ie, starting with the most important variable) and evaluated how the prediction accuracy changed as more variables were included. Selected key predictive variables were then compared with those identified by alternative strategies using (1) the absolute value of coefficients from the LASSO LR model and (2) the prevalence of each variable in the identified ASD cohort.
Separating inpatient and outpatient visits
Considering that the underlying severity of the symptoms could potentially differ by inpatient hospitalisations and outpatient visits,29 we split the number of encounters for each diagnosis and procedure by inpatient and outpatient visit separately and augmented the prediction model with more detailed encounter variables. We compared the prediction performance of the models using the augmented variables with our base case models.
Sensitivity analysis
We performed sensitivity analysis on several modelling assumptions to assess the robustness of our prediction models. Specifically, we strengthened the inclusion criteria for non-ASD subjects by requiring one additional year of enrollment, that is, increased from 4–60 months to 4–72 months. Furthermore, we assessed the potential loss of information due to excluding variables with <1% prevalence, to verify that such a variable prescreening procedure would not miss out on rare but crucial predictive information.
Results
Predicting ASD diagnosis at age of 24 months
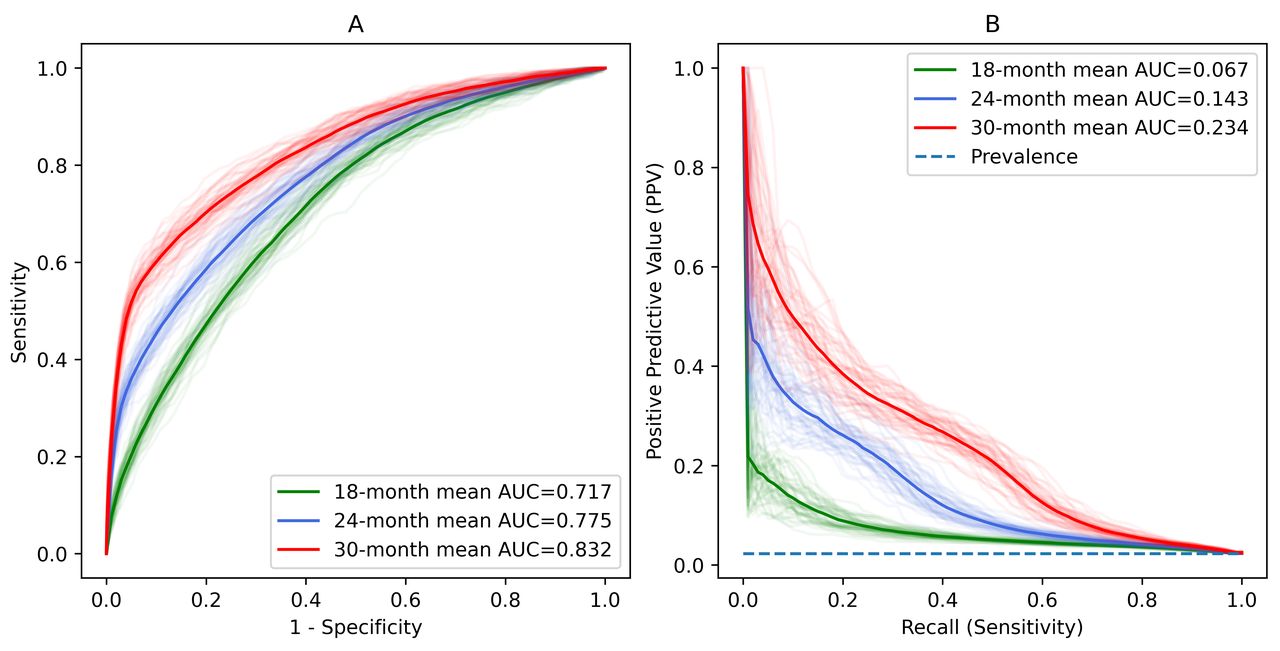
We identified the study cohort consisting of 12 743 ASD subjects and 25 833 non-ASD subjects (more details in online supplemental table S1). When predicting the ASD diagnosis at the age of 24 months in independent testing samples, the LR and RF models achieved the AUROC of 0.758 (95% CI 0.755 to 0.762) and 0.775 (95% CI 0.771 to 0.779), respectively (table 1, figure 2). Compared with the LR model, RF model also showed a higher AUPRC (LR 0.101 (95% CI 0.098 to 0.104); RF 0.143 (95% CI 0.138 to 0.148)) and F1 score (LR 0.193 (95% CI 0.188 to 0.197); RF: 0.246 (95% CI 0.240 to 0.251)). The limit of up to 100 trees in the RF model was deemed sufficient to achieve stable performance. Further increasing the model complexity did not translate to an improvement in prediction accuracy (online supplemental table S2).

Receiver operating characteristic curves (A) and precision-recall (PR) curves (B) for prediction of autism spectrum disorder (ASD) diagnosis at age of 24 months. The prevalence stands for the baseline 2.27% (ie, 1 in 44) ASD prevalence in the general population. AUC, area under curve; LR, logistic regression; RF, random forest.
Performance of LASSO logistic regression and random forest models in prediction of autism spectrum disorder
Predicting ASD diagnosis at different ages
Comparing the prediction models at the ages of 18, 24 and 30 months, we found that the prediction performance increased substantially with the age. Specifically for the RF model, the AUROC increased from 0.717 (0.714–0.721) at age of 18 months to 0.832 (0.828–0.835) at 30 months (table 1). Similarly, the AUPRC increased from 0.067 (0.065–0.069) to 0.234 (0.227–0.240) (figure 3), and F1 score increased from 0.130 (0.125–0.134) to 0.326 (0.322–0.331) from age of 18–30 months. The LR model, although with a lower prediction accuracy compared with the RF model in general, also showed a consistently increasing prediction performance as the age increased.
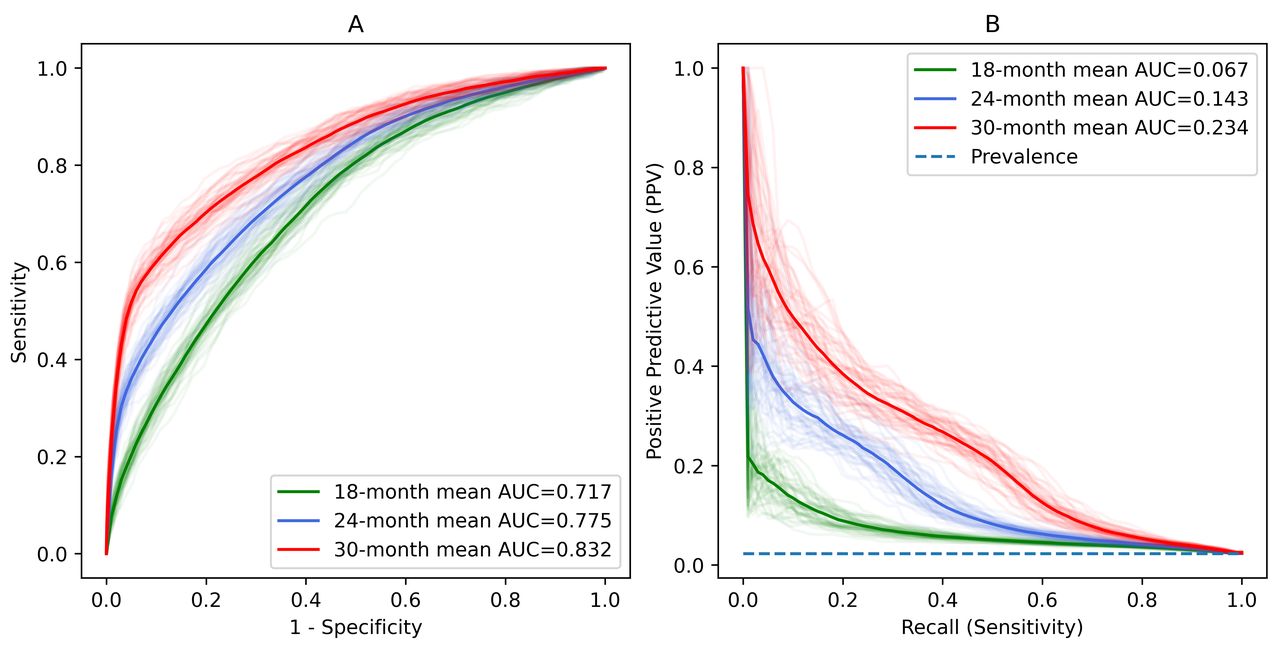
Receiver operating characteristic curves (A) and precision-recall curves (B) for prediction of autism spectrum disorder at ages of 18, 24 and 30 months, respectively, by the random forest model. AUC, area under curve.
Identifying key predictive variables
As the RF model included more variables following the importance order by the Gini index, it showed higher AUROC (online supplemental figure S2). For prediction at age of 24 and 30 months, 30–40 most important variables were sufficient to achieve stable prediction performance with AUROC, whereas for an earlier age of 18 months, the top 50 important variables contributed to most of the prediction performance, while including additional variables could continue to marginally improve the prediction performance. We closely examined the 50 most important variables of the RF model (ranked by Gini index) and the LR model (ranked by the median absolute value of the coefficient) for prediction at age of 24 months (online supplemental figure S3). The identified important variables included sex, developmental and nervous system disorders, psychological and psychiatric services, respiratory system infections and symptoms, gastrointestinal-related diagnosis, ear and eye infections, perinatal conditions, and ED visits, which have also been seen as separate risk factors associated with ASD cases in the clinical literature. The key predictors of the RF model were also highly consistent with high prevalence variables, sharing 47 out of 50 most common variables in the ASD cohort (online supplemental figure S4).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
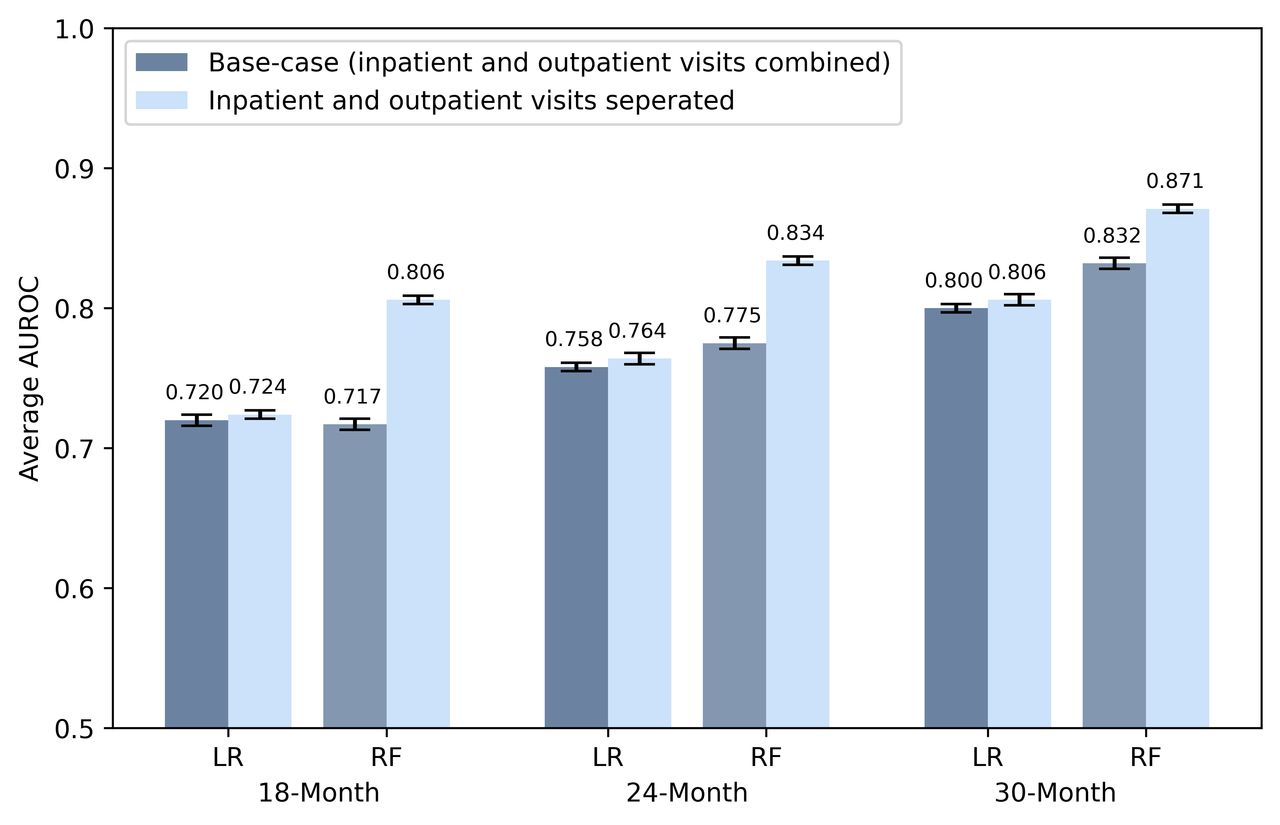
Comparison of area under the receiver operating characteristic curve (AUROC) with combined versus separated inpatient and outpatient encounters by LASSO logistic regression (LR) and random forest (RF) models, at the age of 18, 24 and 30 months, respectively. Error bars in the figure represent the 95% CIs based on results from 50 replications of independent runs. LASSO, least absolute shrinkage and selection operator.
Prediction using separated inpatient and outpatient data
Separating inpatient and outpatient encounters further increased the AUROC for prediction at the age of 24 months to 0.766 (95% CI 0.762 to 0.769) in the LR model and 0.834 (95% CI 0.831 to 0.837) in the RF model. At the target sensitivity of 40%, the RF model achieved a higher specificity of 96.4% (95% CI 96.2% to 96.5%) with a PPV of 20.5% (95% CI 19.8% to 21.1%), outperforming the existing screening tool M-CHAT/F (with a sensitivity of 38.8%, specificity of 94.9% and PPV of 14.6%). We found that using claims data separated by inpatient and outpatient visits improved the prediction performance consistently across all ages (figure 4).
Robustness check and sensitivity analysis
With a more stringent inclusion criterion for non-ASD subjects by requiring a longer full enrollment period up to 72 months (vs 60 months in our base case), we found that the prediction performance had modest improvement (online supplemental table S3). It could be partially attributed to the fact that with longer years to ascertain the non-ASD cohort, children would be less likely to be misclassified. We also verified that including the low-prevalence variables would not result in substantial differences but only marginal changes of AUROC within 0.01 across all model specifications.
Discussion
Early identification is vital for children with ASD to ensure their access to timely intervention and to optimise long-term outcomes. In this study, we demonstrated the feasibility of predicting ASD diagnosis at early ages using health claims data and machine learning models. We found that LASSO LR and RF models achieved an overall AUROC above 0.75 when predicting ASD diagnosis at age of 24 months. Our results also showed that prediction performance increased with age at the time of prediction. This is reasonable because more clinical information accumulated over a longer follow-up period since birth may contain more distinctive patterns to effectively differentiate children with ASD. The prediction models developed in our study are clinically interpretable. Key predictors, such as sex (male), developmental delays, gastrointestinal disorders, respiratory system infections and otitis media have shown strong predictive values for ASD diagnosis, which are in line with previous clinical studies that have shown these symptoms being associated with ASD children. Finally, our study showed that separating inpatient and outpatient claims as predictors could further improve the prediction accuracy.
In our study, both LASSO LR and RF models showed promising accuracy in predicting ASD diagnosis based on an individual’s medical claims data. This robust finding implies that there may exist distinct patterns in health conditions and health service needs among young children with ASD, well before the onset of most hallmark ASD behavioural symptoms. Such predictive signals can be easily extracted from the electronic health records or medical claims administrative data, and used for the early identification of ASD cases. We also observed differences in the performance between the two models. The RF model outperformed the LASSO LR model in general, likely because, with its tree-based model structure, the RF model is better at capturing complex interactive effects among the predictor variables to distinguish between the ASD and non-ASD cases, whereas the LR model synthesises the effects of multiple variables additively. The advantage of the RF model became more salient when input variables were separated by inpatient and outpatient claims into a more granular level.
Our study has made an important contribution to applying health informatics in the field of ASD. Although there exists a plethora of literature identifying individual risk factors of ASD, using large healthcare service data and machine learning models to systematically predict ASD diagnosis has remained much less explored. Unlike existing clinical informatics studies that focused on detecting ASD subtypes,16 17 we aim to detect ASD cases among the general children population, that is, the early detection. This could be particularly challenging due to the low prevalence of ASD in the general population (ie, a highly imbalanced dataset), and the scarcity of information available at such a young age. Nevertheless, our model showed promising prediction performance. The RF model with separated inpatient and outpatient encounters achieved a specificity of 96.4% at a sensitivity of 40% for the ASD prediction at the age of 24 months, outperforming the accuracy of the existing ASD-specific screening tool (sensitivity: 38.8%; specificity: 94.9%) from a clinical observational study.7 It is worth noting that under a similar ASD prevalence (2.2%), our model showed a higher PPV (20.5% vs 14.6%).
Our prediction model for ASD diagnosis could lead to a significant impact on the screening strategies for ASD in young children. Although the AAP guidelines recommend universal screening in all children, it has been debated that, without the perfect screening tool, universal screening may result in overburdened diagnostic services in the healthcare system as these clinical resources are in extremely short supply.30 Our prediction models have demonstrated promising improvement over the existing ASD screening tool by using clinical information, which could potentially serve as a ‘triaging tool’ for identifying high-risk patients for diagnostic evaluation. Moreover, the models only based on health claims data makes it practically feasible to integrate into an EHR system or insurance claims database. It could further enable an automatic screening tool, which can continuously monitor an individual’s risk as new diagnosis and procedure information emerges, and send reminders to patients or providers for a timely clinical assessment if necessary. On the other hand, it is possible that some diagnosis and procedure information appear after a concern that the child had autism has already existed, such as following a positive screening event, which could alter the course of subsequent clinical events. As such, our prediction model is not designed to direct the screening decisions, but rather a tool to enhance the screening accuracy. If more detailed electronic health record data were available, the proposed risk prediction model could be further extended by incorporating screening results with clinical information, or by differentiating the clinical information before versus after the screening events, to further improve the accuracy of identifying high-risk ASD cases for further diagnostic evaluation.
Our study has several limitations. First, diagnosis of ASD established only based on existing diagnosis codes from claims data could be inaccurate and unreliable sometimes in practice. We followed a validated approach in ASD health service research literature to identify the ASD cohort in our study.31 Second, the absence of ASD diagnosis codes in one’s health record may not necessarily indicate an individual not having ASD, especially for children born in later years, due to limited follow-up time prior to the cut-off date in the database. Thus, we required full enrollment up to 60 months without ASD diagnoses to identify the non-ASD cohort, and verified the robustness of our base case results in a sensitivity analysis requiring full enrolment up to 72 months. Third, as autistic children are likely to have a wide range of comorbid conditions with various frequencies, for individuals who do not present comorbid conditions from the past healthcare encounter data, our model may provide limited value. Our risk prediction model can be further augmented by additional information other than information from the health claims database, such as ASD/developmental screening results and behaviour-related information from a more comprehensive EHR dataset in future studies. Lastly, the diagnosis and procedure codes in insurance claims data may be subject to variabilities and irregularities. Instead of the original detailed clinical codes, we used aggregated CCS categories for diagnoses and procedures for more robust clinical measures.
Conclusions
Using real-world health claims data and machine learning methods, we developed a prediction model that can successfully predict ASD diagnosis for children under 30 months with promising prediction accuracy. Our model also identified the important predictors for the diagnosis prediction, which showed meaningful clinical relevance and intuition. Our predictive modelling approach could potentially be generalised to broader clinical settings for predicting the diseases that may show early signals from past healthcare service encounters in claims or EHR data. Future studies could explore the prediction of ASD diagnosis dynamically over time as new healthcare encounter occurs, and investigate how validated risk prediction models could be integrated and used to inform ASD screening strategies.
Data availability statement
Data may be obtained from a third party and are not publicly available.
Ethics statements
Patient consent for publication
References
Supplementary materials
Supplementary Data
This web only file has been produced by the BMJ Publishing Group from an electronic file supplied by the author(s) and has not been edited for content.
Footnotes
Contributors GL, QC and Y-HC conceived of the presented idea, and developed it with support from GL and QC. Y-HC cleaned and preprocessed the data, developed prediction models, and performed model evaluations. All authors interpreted the model results. Y-HC and QC drafted the manuscript, which was critically revised by all authors. QC is the guarantor of the project.
Funding This work has been supported by Penn State Social Science Research Institute Level 1 Seed Grant (QC, GL), Penn State College of Engineering Multidisciplinary Research Seed Grant (Y-HC, QC, GL) and NIH R21 grant: 1 R21 MH119480-01A1 (GL, LK).
Competing interests None declared.
Provenance and peer review Not commissioned; externally peer reviewed.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.