Article Text

Abstract
Introduction The number of new biomedical manuscripts published on important topics exceeds the capacity of single persons to read. Integration of literature is an even more elusive task. This article describes a pilot study of a scalable online system to integrate data from 1000 articles on COVID-19.
Methods Articles were imported from PubMed using the query ‘COVID-19’. The full text of articles reporting new data was obtained and the results extracted manually. An online software system was used to enter the results. Similar results were bundled using note fields in parent–child order. Each extracted result was linked to the source article. Each new data entry comprised at least four note fields: (1) result, (2) population or sample, (3) description of the result and (4) topic. Articles underwent iterative rounds of group review over remote sessions.
Results Screening 4126 COVID-19 articles resulted in a selection of 1000 publications presenting new data. The results were extracted and manually entered in note fields. Integration from multiple publications was achieved by sharing parent note fields by child entries. The total number of extracted primary results was 12 209. The mean number of results per article was 15.1 (SD 12.0). The average number of parent note fields for each result note field was 6.8 (SD 1.4). The total number of all note fields was 28 809. Without sharing of parent note fields, there would have been a total of 94 986 note fields.
Conclusion This pilot study demonstrates the feasibility of a scalable online system to extract results from 1000 manuscripts. Using four types of notes to describe each result provided standardisation of data entry and information integration. There was substantial reduction in complexity and reduction in total note fields by sharing of parent note fields. We conclude that this system provides a method to scale up extraction of information on very large topics.
- COVID-19
- data management
- software
- health information management
- public health
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
Introduction
With >1 000 000 new articles per year1 2 it is nearly impossible to comprehensively assimilate newly published literature.3 4 PubMed and Google Scholar are powerful search tools, but the product is only a set of citations. Systematic reviews have a short life cycle5 and the process of establishing continuity between reviews is not well defined. Tools that facilitate reading, describing and integrating data are limited. Linking results across multiple manuscripts is difficult.3 Tagging articles with keywords may help bundle sets of manuscripts but is a poor substitute for quality extraction of results.
We present pilot results extracting and integrating data from 1000 COVID-19 publications using a new online system and discuss the scalability and public dissemination of the information.
Methods
A single account was used for the COVID-19 database (Refbin.com, Plomics, Shelburne, Vermont). Refbin retrieved citations from PubMed using COVID-19 as the search term. Articles that reported new data were selected (1000 of 4236). The results were manually extracted from full-text articles. Reviewers included six undergraduates, five postgraduate and three faculty. The average number of articles per reviewer was 132 (SD 243).
The extracted results were entered manually into the COVID-19 library as independent units of information. Each result was described by a set of note fields. The note fields were arranged in parent–child order and included (1) result, (2) description of the result, (3) population and (4) topic. The result note field occupied the lowest child note field. The citation was dragged to the result note field and was automatically linked to all parent note entries (see online supplemental methods for additional details).
Supplemental material
Results
From 1000 publications, 12 209 individual results were extracted. These were organised under 15 first-level topic note fields (online supplemental figure 1). The order, pattern and total number of parent notes varied for each extracted result (figure 1). The average number of note fields required to describe an extracted result was 7.78 (SD 1.42) (online supplemental table 1).
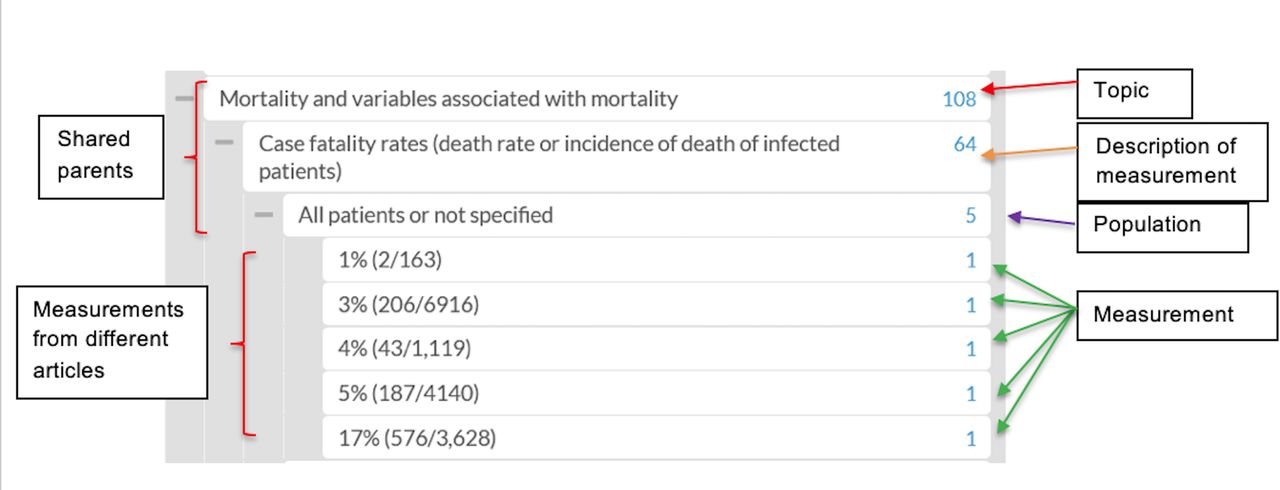
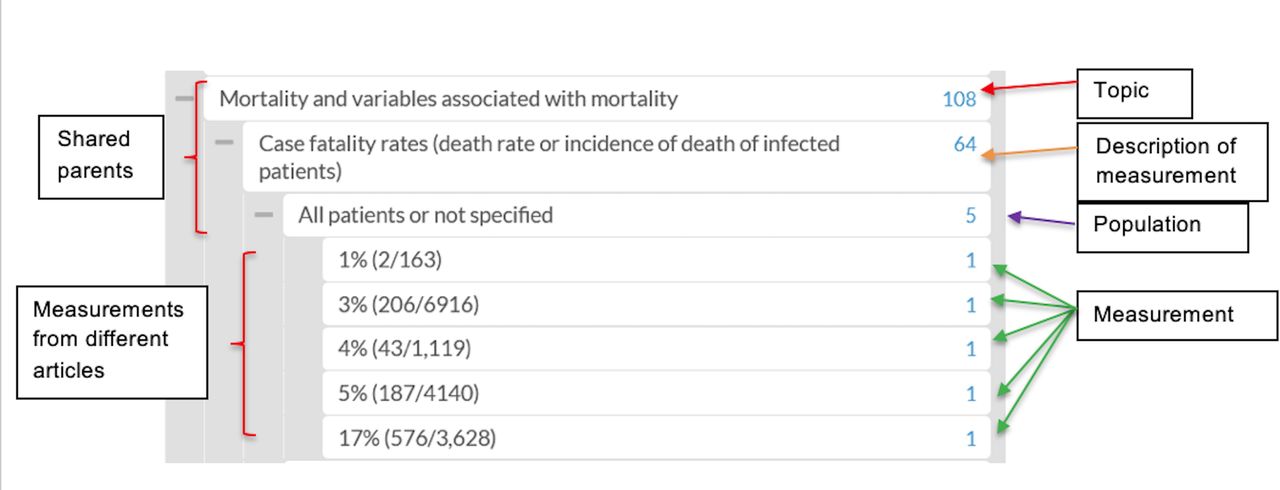{kind=link}
Screenshot of multiple entries of case fatality rates at the same hierarchical level sharing the same parents and four types of note fields. The number on the right edge of the note field is a citation counter. The parent note fields display the sum of citations affiliated with its children.
The results from one manuscript were entered into multiple relevant locations throughout the database. The results from multiple manuscripts with similar features, for example case fatality rates, were bundled together. These similar results were entered into the same note field level and then could share parents (figure 1).
Sharing of parent note fields allowed substantial reduction in the total number of note fields and simplification of data entry. Without sharing of parents, the total number of all note fields would have been 94 986. With sharing of parents, the total number of note fields was reduced ~70% to 28 613 total note fields. This represents an absolute reduction of 66 373 note fields (online supplemental figure 2).
To assess communication tools, 719 corresponding authors from 1000 publications were invited by email to obtain a personal Refbin account that included a read-only live portal to the COVID-19 library. This was accepted by 21% (148 of 719) and represented authors from 22 different countries. A publicly available website (COVIDpublications.org) was also created that displayed a live version of the COVID-19 library.
Discussion
Four types of note fields were sufficient to describe each of the wide variety of results extracted from 1000 articles. Similar results shared parent note fields. This facilitated integration of data by creating frameworks to bundle results from different articles. This resulted in 70% reduction in the total number of note fields.
Online review methods minimised the frequency of scheduled meetings. Online group discussions were reserved for more challenging issues. Treating the extracted results as independent units of information allowed the results from one article to be placed in different library locations. This also allowed similar results from multiple articles to be integrated into a single location.
This pilot study describes a system that facilitates multiple individuals to read, describe and integrate results in a scalable manner. A live portal to the COVID-19 library was initiated for 148 researchers from 22 countries. A public version of the COVID-19 library was accomplished (COVIDpublications.org). This sets the stage for researchers to work together on areas of common interest and enhanced sharing of information across international borders.
Limitations of this study include dependency on the narrative language to describe a result. This limitation is mitigated by using the four note field types to describe each result, which helps standardise descriptions. Manual extraction of information is time-consuming. However, by providing the information as in this pilot study, time investment by a larger population of users may potentially be reduced. Reproducibility is a potential limitation. This was somewhat mitigated in this pilot study by using extraction rules and oversight from multiple reviewers. Formal assessment of reproducibility will be a goal of future work.
Large-scale healthcare issues such as COVID-19 or opioid use disorder have dramatic adverse effects on personal and global health. The efforts of thousands of researchers worldwide working on a health problem will be sped up if their collective research output was better organised and extracted into a user-friendly database. This pilot study demonstrated the feasibility to accomplish this task. Treating results like units of information provides freedom to assemble and integrate information from multiple manuscripts in a logical manner. This method of extraction using parent–child relationships and automated linkages facilitates integration of information and makes entry of data easier, especially by less experienced reviewers. We conclude that this system provides a platform to scale up extraction of information on very large topics to be managed by multiple individuals residing in diverse locations.
Ethics statements
Patient consent for publication
Ethics approval
This study does not involve human participants.
Supplementary materials
Supplementary Data
This web only file has been produced by the BMJ Publishing Group from an electronic file supplied by the author(s) and has not been edited for content.
Footnotes
Contributors All authors contributed equally.
Funding The authors have not declared a specific grant for this research from any funding agency in the public, commercial or not-for-profit sectors.
Competing interests MB and DK have ownership interest in Plomics. SL, IF, CT-L, SR and JP declare no financial or competing interests.
Provenance and peer review Not commissioned; externally peer reviewed.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.