Article Text

Abstract
Objective How health researchers find secondary data to analyse is unclear. We sought to describe the approaches that UK organisations take to help researchers find data and to assess the findability of health data that are available for research.
Methods We surveyed established organisations about how they make data findable. We derived measures of findability based on the first element of the FAIR principles (Findable, Accessible, Interoperable, Reproducible). We applied these to 13 UK health datasets and measured their findability via two major internet search engines in 2018 and repeated in 2021.
Results Among 12 survey respondents, 11 indicated that they made metadata publicly available. Respondents said internet presence was important for findability, but that this needed improvement. In 2018, 8 out of 13 datasets were listed in the top 100 search results of 10 searches repeated on both search engines, while the remaining 5 were found one click away from those search results. In 2021, this had reduced to seven datasets directly listed and one dataset one click away. In 2021, Google Dataset Search had become available, which listed 3 of the 13 datasets within the top 100 search results.
Discussion Measuring findability via online search engines is one method for evaluating efforts to improve findability. Findability could perhaps be improved with catalogues that have greater inclusion of datasets, field-level metadata and persistent identifiers.
Conclusion UK organisations recognised the importance of the internet for finding data for research. However, health datasets available for research were no more findable in 2021 than in 2018.
- information management
- medical informatics
- record systems
Data availability statement
Data are available in a public, open access repository. Data are available freely online, including internet search results and summary survey notes. Original survey notes have not been shared to protect respondent confidentiality. Mendeley Data—internet search results: https://data.mendeley.com/datasets/fp9mpj3t9r/1. Mendeley Data—semistructured interviews: https://data.mendeley.com/datasets/j49bgj7nmn/1. Additional data following reviewer suggestions are also available via Figshare: https://doi.org/10.48420/14791590.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
Summary
What is already known?
Science benefits hugely from the sharing and reuse of datasets.
There are many barriers to reuse, one of which is researchers not knowing what datasets already exist that may be relevant to their analysis.
What does this paper add?
Organisations say that they want to make datasets more findable online, but that the time and personnel to achieve this is often lacking.
We assess findability of UK health datasets in online searches.
We found that this aspect of findability is no better in 2021 than it was in 2018.
Online catalogues of health data rarely include identifiers that would enable proper referencing or field level metadata to indicate suitability for reanalysis.
Introduction
With 65 million people, a single payer health system, a unique identifier for its citizens’ health data, and long-standing population-wide electronic health records (EHRs), the UK is uniquely placed to harness insights from routinely collected health data. UK primary care has been an early adopter of information technology, with most practices computerising prescribing and clinical record keeping over the past 20 years.
EHRs are collected routinely as part of direct care in the National Health Service (NHS), with tens of millions of records in existing ‘e-cohorts’ based on geography or diagnosis.1–4 An e-cohort can enable researchers to ‘investigate the broadest possible range of social and environmental determinants of health and social outcomes by exploiting the potential of routinely collected datasets’.5 Some e-cohorts thus include other detailed data, for example, the Wales E-Cohort for Children includes educational attainment.6 There is an ambition to sequence 5 million NHS patients’ genomes.7 Reuse of such data is advancing research, from disease aetiology to drug discovery, translational research and public health. There is a drive across many fields towards the sharing and reuse of health data.8 9
Apart from several long-standing and widely used national e-cohorts, for example, the Clinical Practice Research Datalink (CPRD),10 11 there exist regional e-cohorts12–14 that are known anecdotally to researchers connected to data providers, but are less well known by the wider research community. Lack of familiarity with existing e-cohorts may reduce their utilisation for research, weaken transparency and replicability of research and lead to duplication of effort in generating new equivalent datasets.8 15
The FAIR principles16 were developed to guide sharing of scientific data and maximise the discovery, evaluation and reuse of such data. These four principles state that published data should be findable, accessible, interoperable and reusable. This article focuses on the principle of findability. The FAIR principle of findability recommends that data (or metadata) should be:
Assigned a unique and persistent identifier.
Described by rich metadata which links explicitly to the data described.
Indexed in a searchable resource.
This project aimed to describe the current findability of routinely collected e-cohorts from the UK to a person (a researcher or interested citizen) using internet search engines. Specific objectives were: (1) to identify current approaches and potential barriers to increasing findability by surveying established organisations that facilitate access to health data (including e-cohorts) for research, and (2) to assess the findability of a target list of e-cohorts directly through internet searches and indirectly via online health data catalogues and see how findability changed between 2018 and 2021.
Methods
Assessing approaches to findability at UK organisations supplying data to researchers
One route of access to routinely collected data for research is via organisations acting as data curators, providers, safe havens or research services. We wanted to understand what these organisations do to make their datasets findable and what obstacles they face in doing so. The datasets available may extend beyond health, but all are confidential datasets based in UK public sector organisations so findability practices should be transferable.
We conducted telephone surveys with staff from such organisations. We contacted the organisations with a participant information sheet via email, using publicly available contact information. These organisations were those of which the authors were aware, through their prior research or through participation in national initiatives such as the Farr Institute17 or Safe Data Access Professionals.18 As well as organisations specialising in health research, we included five that host other types of confidential data to understand their practices (eg, Her Majesty’s Revenue and Customs (HMRC) Data Lab; see asterisks in table 1). Up to two follow-up emails were sent to centres that did not initially respond.
List of public sector organisations that took part in the surveys
Semistructured telephone surveys were conducted by RMJ and EG in April and May 2018 and focused on how organisations currently make their data findable, future plans to increase findability and any barriers to making data more findable. The HMRC Data Lab responded via email. An interview data collection sheet was developed from discussion among coauthors based on a preliminary interview with Electronic Data Research and Innovation Service conducted jointly by RMJ and EG. Notes were taken by RMJ or EG during each survey. Results were compiled by summarising and counting responses.
Assessing findability of e-cohorts for health research
We used several approaches to explore findability of e-cohorts from the perspective of health researchers. First, we quantified how frequently e-cohorts appeared in a series of internet searches. Second, we searched the health data catalogues for the prespecified e-cohorts, and for those e-cohorts that were present in the health data catalogues, we assessed whether the e-cohorts met the FAIR criteria of having rich metadata and a persistent identifier.
We aimed to replicate searches that might be carried out by a researcher trying to find data for their research or a member of the public curious about routine health information that is used in research. The study team, which has significant experience of research with health data and was involved in national initiatives such as the Farr Institute17 and Health Data Research UK,19 compiled a list of UK health-related e-cohorts known to them, without consulting the internet. This list served as targets for our searches (table 2), including well-known national datasets (eg, CPRD) and smaller, regional datasets of which the team had prior knowledge. The list also contained a number of data organisations, which provide access to e-cohorts.20 Two kinds of search were performed to try to find these datasets.
Description of target UK e-cohorts assessed for findability in direct and indirect searches
Search using general internet searches
Search engines Google and Bing were searched separately in March 2018 (by EG and RMJ) and May 2021 (by EG and GT) using each of the following terms: health data research; acute care research datasets; community care research datasets; electronic health records; health datasets; health records research; hospital research datasets; primary care research datasets; secondary care research datasets and tertiary care research datasets (figure 1).
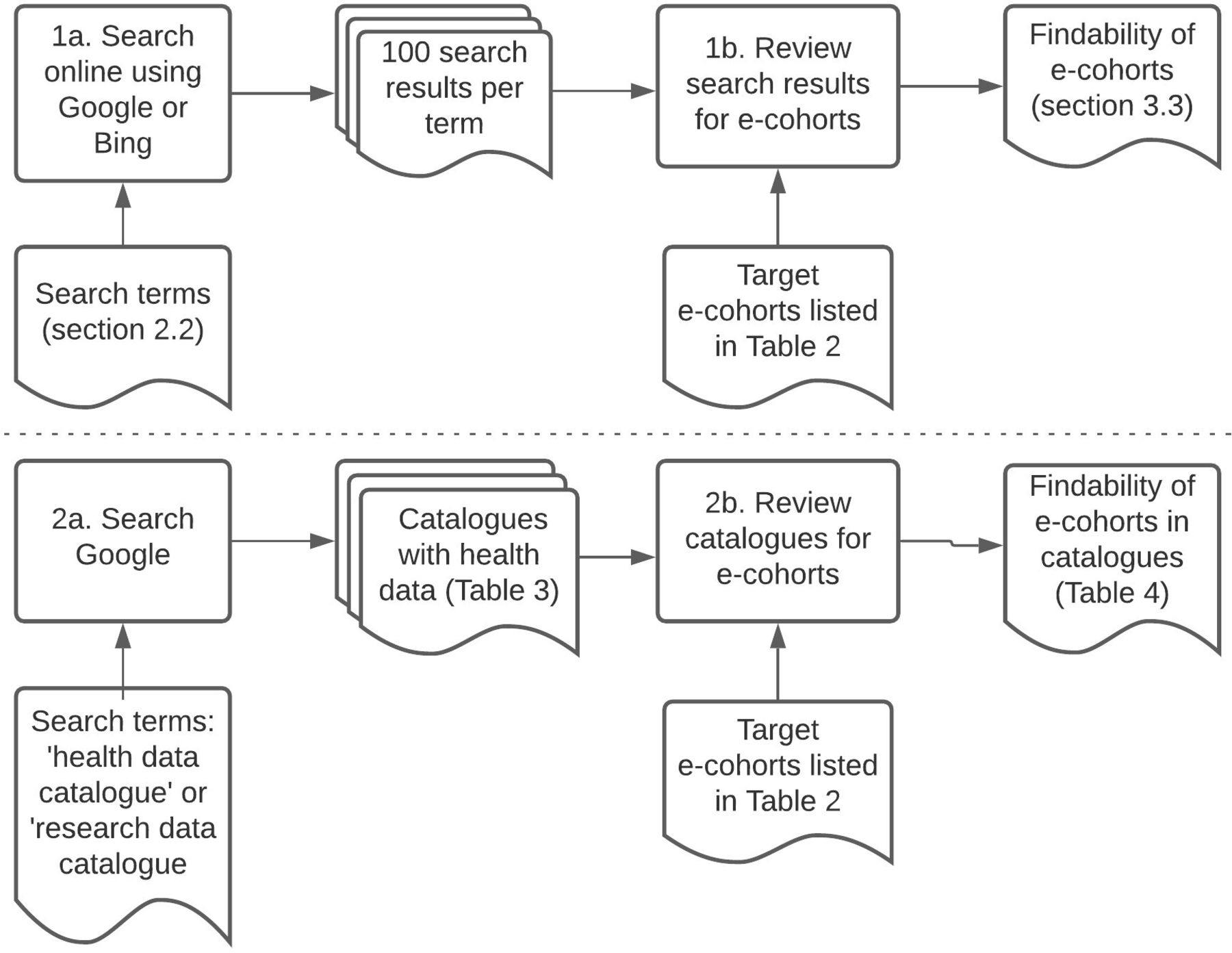
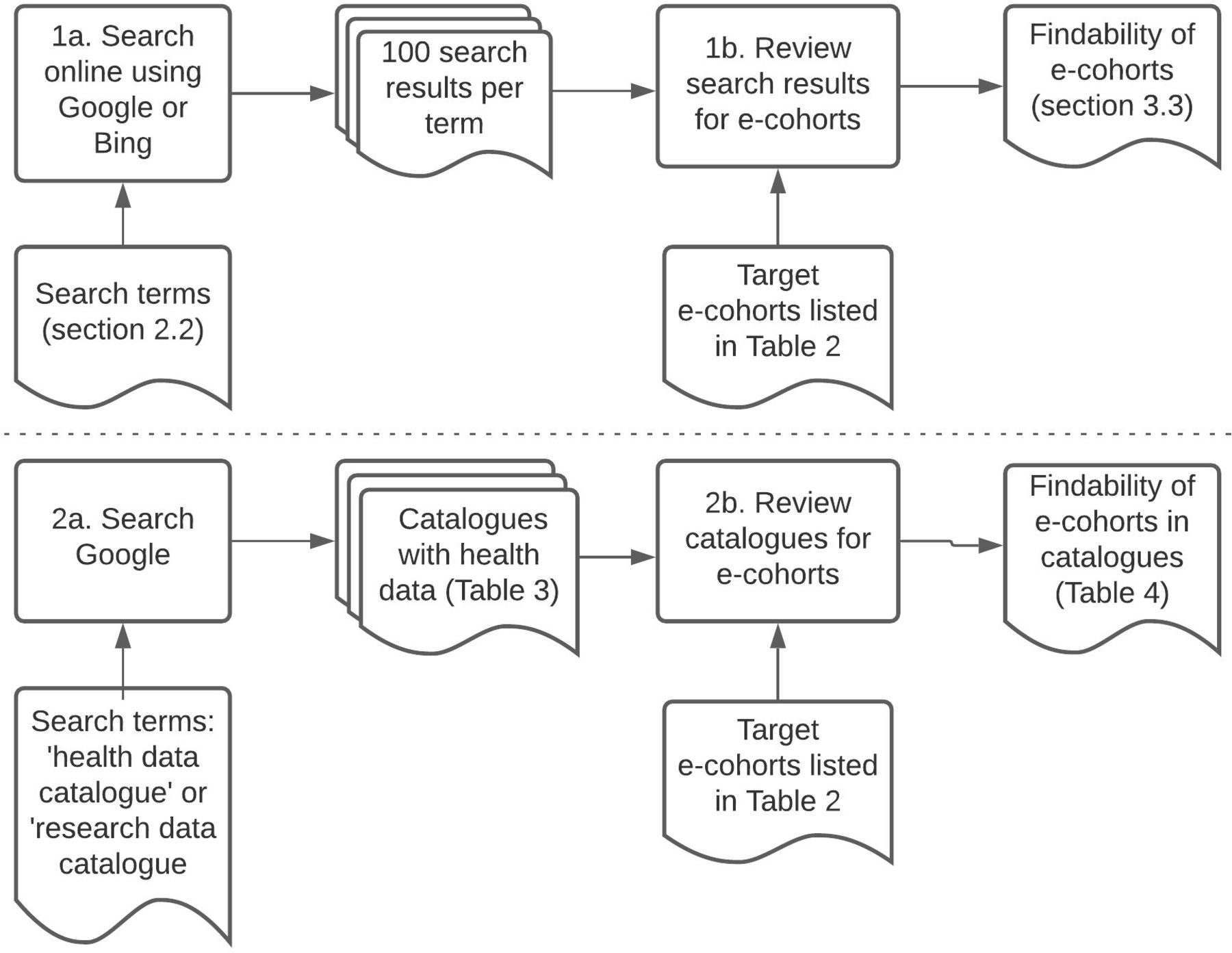{kind=link}
Internet search process—looking for health datasets via two popular, general search engines (1) and via catalogues (2).
We used plain text search terms (no wildcards) to replicate simple searches the way someone might initially explore the public internet for relevant websites. We avoided terms such as ‘case control study’ or ‘clinical cohort’ as these relate to particular study designs, whereas we wanted to find routinely collected datasets. We wanted to replicate a well-motivated search and give a good chance of finding relevant results so we reviewed multiple pages of search results up to the hundredth listing. Search results were screened for reference to the target datasets (figure 1, step 1b). These references were either direct (the search result was itself the target’s website) or indirect (a link in the search result led to the target).
Search using research data catalogues
To identify existing catalogues of UK health data, Google was searched using the terms ‘health data catalogue’ or ‘research data catalogue’ (omitting the quotation marks). The first 100 search results were screened for our targets (figure 1, step 2b).
Search using Google dataset search engine
After our 2018 searches were conducted, a new search engine was available from Google dedicated to finding datasets. In 2021, two authors (GT and EG) each searched for our 10 search terms in Google Dataset Search and reviewed the top 100 search results for our 13 target datasets.
Findability was assessed according to the following criteria:
Was a direct link found from Google or Bing searches?
Was there any indirect link to the e-cohort from the Google/Bing search results which might prompt a researcher to investigate further?
Was the e-cohort listed in one of the catalogues that were found by searching the internet for health data catalogues? If so, as defined by the FAIR principles, what depth of metadata were available and was there a persistent identifier?20
Data sharing
We have made data freely available online on Mendeley and Figshare including survey participant information sheet and summary notes (https://data.mendeley.com/datasets/j49bgj7nmn/1), 2018 internet search results (https://data.mendeley.com/datasets/fp9mpj3t9r/1) and 2021 search results and protocol (https://doi.org/10.48420/14791590). Original survey notes have not been shared to protect respondent confidentiality.
Results
Survey findings: current practice as reported by established organisations
Of the 18 centres contacted, 12 agreed to be surveyed (table 1) and 6 did not respond. Of the 12 organisations that responded to the survey, 11 reported to share public-facing information about the available datasets (for Connected Health Cities North East and North Cumbria, a catalogue was under development at the time of the interview, now available at https://github.com/connectedhealthcities/nenc-chc). Some had different levels of access where more sensitive information was restricted to an approved audience. Metadata were provided in various ways, including through interactive catalogues (based on a number of software packages), static websites, PDFs and Excel files. The UK Data Service, Consumer Data Research Centre and Administrative Data Research Network used the DDI (Data Documentation Initiative) metadata standard21 to describe the datasets. The other nine organisations did not use a standard metadata schema.
Respondents talked about many other means of increasing findability, including using social media, newsletters, scientific articles and conference presentations to publicise their datasets. They were also interested in finding out what researchers wanted; three used Google Analytics to understand what people were looking for and others described discussions with researchers to better understand their needs. One organisation described a more proactive approach, using calls for expressions of interest to find and support researchers interested in using their data. For further details on approaches to findability, see the supplementary files available on Mendeley Data (https://doi.org/10.17632/j49bgj7nmn.1).
Perceived challenges to findability according to established organisations
Respondents were also asked for perceived barriers to data findability. This prompted a broad range of responses, which are summarised below and detailed in the supplementary files available on Mendeley Data (https://doi.org/10.17632/j49bgj7nmn.1). Issues include: datasets submitted with poor quality metadata, no widely adopted metadata standards or cataloguing technologies. Shortages in expertise and time were also cited, as was the view that data providers and funders did not prioritise curation of metadata and that the role of data curators is underappreciated. Many respondents recognised that more support was needed to curate good quality metadata. The challenges of dealing with the inherent variability of routinely collected health data for both curators and researchers and lack of appropriate metadata standards for health data were also raised.
When asked about plans to improve findability, respondents covered topics as diverse as making better use of existing web tools (cited most often), improving metadata quality, offering more support to research users and overlapping with other developments in the repository operations such as data linkage or migration (cited least often). Some organisations reported actively exploring new tools to replace their existing catalogues. Respondents highlighted that a good catalogue needs to contain entries for a wide range of datasets and have a usable search tool, developed with an understanding of researchers’ needs.
Findability of target e-cohorts and data organisations using general internet search engines
Internet searches in 2018 found direct links to the websites of 8 of the 13 target e-cohorts listed in table 2. When clicking on links within each search result, all 13 targets were indirectly findable. For further details see the supplementary files available on Mendeley Data (https://doi.org/10.17632/fp9mpj3t9r.1).
In 2021, there were direct links to 7 of the 13 target e-cohorts listed in table 2, but when clicking on links within each search result 8 were indirectly findable. See supplementary files available on Figshare (https://doi.org/10.48420/14791590).
Findability of target e-cohorts and data organisations using health data catalogues
In 2018 we identified nine catalogues of UK-based e-cohorts through internet searches (table 3). Six catalogues referred to 1 or more of the 13 target e-cohorts listed in table 2, while 3 catalogues did not reference any of the targets. In 2021 two of those nine catalogues were inaccessible, and, among the remaining seven catalogues, one listed more target e-cohorts (from one in 2018 to four in 2021).
Catalogues of UK-based e-cohorts found through general internet search engines in 2018 and the number of target e-cohorts within them in 2018 and 2021
In 2018 all the catalogues included dataset-level metadata (descriptive, structural or administrative metadata about the dataset). The Health Data Finder, particular entries in the NHS England Data Catalogue, the Perinatal Mental Health (published by Public Health England) and Social Services Improvement Agency Data Catalogue had field-level metadata (descriptive, structural or administrative metadata held at the level of individual fields). None of the catalogues attached DOIs to their entries. The results are summarised in table 4. In 2021, among the seven catalogues still accessible, their findability in terms of metadata detail and identifiers was unchanged. Nine additional catalogues were found in the searches in 2021, seven of which included persistent identifiers but not always field level metadata and only two included target e-cohorts.
Findability of target e-cohorts and data organisations in 2021 using Google dataset search
Using the Google dataset search, all but 1 of our 10 searches produced over 100 results (searching for ‘tertiary care research datasets’ only produced 30 results). Among all available search results up to 100, 3 of the 13 target datasets were found once (HES, CPRD and SAIL).
Discussion
We sought to understand how easily a person could discover e-cohorts from the UK via internet search engines. We used a telephone survey to understand how organisations try to make data findable and measured how findable e-cohorts were across two internet search engines. In our survey, findability was recognised as valuable, however those managing e-cohorts were still exploring how to harness the power of the internet to improve findability. Using internet search engines, we found a wide range of e-cohorts and catalogues, but between 2018 and 2021 neither the findability of target e-cohorts in the top 100 results nor in catalogues had improved. If anything, findability had decreased slightly. Target e-cohorts were less findable using a new, dedicated dataset search than a general internet search engine. While established national e-cohorts were found directly through search engines, several catalogues and smaller, local or specialist e-cohorts were only found indirectly through other webpages. A crucial factor appears to be the coverage of e-cohorts listed in catalogues or specialist search tools.
Many authors have argued for improved findability, but empirical studies to assess findability have been rare and have not previously been done for UK health data. In the FAIR principles,16 findability requires that datasets have a globally unique and persistent identifier, are described with rich metadata which explicitly include that identifier and are registered or indexed in a searchable web catalogue. In the UK, there have been government-commissioned reports into how FAIR research information is, which recognised the importance of a sector-specific approach but said little about health and did not measure findability.22 Wilkinson et al proposed a set of metrics and a design framework for a FAIRness assessment23 and this framework has been applied to omics data.24 That assessment takes a machine-led approach, that is, whether a dataset is findable, accessible, interoperable and reusable without human intervention. We took an alternative starting point, assessing findability using the searches that might be carried out by a person trying to find e-cohorts. The importance of the public internet in providing search engines that index metadata to make data findable has been recognised,25 although others have highlighted challenges to implementing the FAIR principles for online searches.26 Such publications describe and debate what findability is or should be, but they do not offer an empirical assessment of findability and their claims that improving findability for machines will improve findability for humans are untested. A toolkit was published in 201927 that includes at least three metrics of whether or how easily datasets and other resources can be found using internet searches28; our methods fall in this vein. Looking back to just before our first online searches, a paper from 2016 envisaged a community to advance the FAIR principles (including searchability) in the life sciences,29 and in 2017 researchers highlighted the need for better web-based identifiers for life sciences datasets30 and for improved online discoverability and standardisation for UK health data.31 Our 2021 results show many of those lessons still need to be heeded.
Our finding that some regional e-cohorts had by 2021 become less findable than national counterparts and that some catalogues had become inaccessible has implications for those working to increase data findability. Community efforts and standardisation have been advocated by researchers as the best way to implement the FAIR principles.32 One approach has been to collate metadata centrally, as was done recently for opthalmology.33 Centralised repositories and dedicated data search tools may be increasingly important for fostering findability as more and more datasets are described online, however we found that not all available datasets are currently listed. Search engines, which are increasingly embedded into catalogues as well as being available for the general internet searches we conducted, enhance the findability of some datasets more than others. For example, CPRD was the most findable of our target e-cohorts in 2018 and 2021 and even increased its presence in search results, while some other target e-cohorts became less findable. As well as creating hubs, we suggest that the health data community also discusses variability in the findability of datasets and use benchmarks for online findability to assess progress.
A large effort as a result of the COVID-19 pandemic has given momentum to new findability tools, such as Health Data Research UK with their new catalogue: the Innovation Gateway.34 COVID-19 data were listed in the catalogue and already found in our 2021 searches. The pace and scale of these developments, which are already producing research insights, are impressive. This may be helped by a more coordinated effort in the NHS under the UK government’s data strategy.35 Such efforts need continued support to enhance coverage, for example, to include more of our target e-cohorts or newer e-cohorts such as OpenSAFELY4 and to boost metadata quality and accessibility.
Our work has some limitations. First, although we tried to contact as many organisations as possible across the UK, not all the ones we contacted were able to participate, and we may have missed some others. We can only speculate on how this has affected our results; it is possible that organisations that did not respond are stretched and chose to prioritise other work over our survey into findability. Second, our prior knowledge of the target e-cohorts probably made it easier for us to find them. Third, when screening search results, we reviewed 100 results per search (approximately 10 pages), two or three pages might be more realistic. We may therefore have overestimated the findability of UK e-cohorts. Fourth, the proprietary nature of search engines makes their operations unclear, for example, the consistency of the search rankings among different users36 or how algorithms may have altered findability between 2018 and 2021. Google and Bing limit automated processing of their search tool26 and manually checking 100 results per search was time intensive.
There are opportunities to extend our approach in further research. It would be useful to study how researchers find and access e-cohorts in practice. The use of wildcards to make searches more flexible, analysis of rankings and use of other search engines could be adopted in future. Comparison across organisations of the investment (time, money) and competencies of personnel working to make e-cohorts findable and accessible could reveal the most efficient methods to inform successful strategies for improving findability.
Based on our findings, we recommend that UK e-cohorts implement the following features to improve their findability: create a unique and persistent identifier, have richer metadata descriptions and ensure they are indexed in a searchable resource either through search engine optimisation of their own website or through catalogues that are highly ranked by search engines.
Data availability statement
Data are available in a public, open access repository. Data are available freely online, including internet search results and summary survey notes. Original survey notes have not been shared to protect respondent confidentiality. Mendeley Data—internet search results: https://data.mendeley.com/datasets/fp9mpj3t9r/1. Mendeley Data—semistructured interviews: https://data.mendeley.com/datasets/j49bgj7nmn/1. Additional data following reviewer suggestions are also available via Figshare: https://doi.org/10.48420/14791590.
Ethics statements
Patient consent for publication
Ethics approval
The University of Manchester Research Ethics Committee does not require approval for studies in which participants are interviewed on subjects within their professional competence, provided that participants are contacted using publicly available details and are provided with an information sheet and data are not attributable to individuals. Those who participated had the opportunity wherever possible to review the manuscript before submission.
Acknowledgments
The authors wish to thank Ben Green, Sarah Al-Adely and Will Hulme for their advice in the planning and data collection phases of this project.
References
Footnotes
Twitter @emble64, @Tilstongeorge, @NielsPeek
Contributors EG, RMJ, NP, ZK and WD designed the study. ST made substantial contribution to summary and analysis of the survey information. GT made substantial contribution to the collection of 2021 search results. EG acted as guarantor. All authors contributed to drafting the paper and providing critical comments, approved the final submission and are accountable for this work.
Funding NP’s work was partially funded by the National Institute for Health Research (NIHR) Greater Manchester Patient Safety Translational Research Centre and the NIHR Manchester Biomedical Research Centre. All the authors except GT were supported by Connected Health Cities, which was a Northern Health Science Alliance (NHSA) led programme funded by the Department of Health and delivered by a consortium of academic and NHS organisations across the north of England. The views expressed are those of the author(s) and not necessarily those of the NHS, the NIHR, the Department of Health or NHSA.
Competing interests None declared.
Provenance and peer review Not commissioned; externally peer reviewed.