Article Text

Abstract
Background and objectives Literature review using search engines results in a list of manuscripts but does not provide the content contained in the manuscripts. Our goal was to evaluate user performance-based criteria of concept retrieval accuracy and efficiency using a new database system that contained information extracted from 1000 COVID-19 articles.
Methods A sample of 17 students from the University of Vermont were randomly assigned to use the COVID-19 publication database or their usual preferred search methods to research eight prompts about COVID-19. The relevance and accuracy of the evidence found for each prompt were graded. A Cox proportional hazards’ model with a sandwich estimator and Kaplan-Meier plots were used to analyse these data in a time-to-correct answer context.
Results Our findings indicate that students using the new information management system answered significantly more prompts correctly and, in less time, than students using conventional research methods. Bivariate models for demographic factors indicated that previous research experience conferred an advantage in study performance, though it was found to be independent from the assigned research method.
Conclusions The results from this pilot randomised trial present a potential tool for more quickly and thoroughly navigating the literature on expansive topics such as COVID-19.
- Information Management
- Online Systems
Data availability statement
Data sharing not applicable as no datasets generated and/or analysed for this study.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
What is already known on this topic
The output of biomedical publication search tools is a set of manuscripts but access to content is restricted.
What this study adds
This study provides evaluation of a new method to extract, repurpose and disseminate information derived from published manuscripts.
How this study might affect research, practice or policy
Despite massive advancements in scientific methods, the science and practice of extraction and integration of information in manuscripts have lagged. We describe a method that advances a new method to improve efficiency of extraction and integration of information.
Introduction
PubMed contains over 32 000 000 publications and this collection grows by approximately 1 000 000 articles each year.1 2 The first step in accessing this wealth of knowledge is to acquire a list of publications through search engines such as PubMed and Google Scholar. The user must then painstakingly comb through full-text articles to find the information they seek.
Community curation platforms such as Wikipedia allow rule-based descriptions of virtually any topic. However, Wikipedia is not designed to provide a comprehensive summary of the information contained within a set of publications. Community curation has been used on databases such as UniProt (model organism genome database) but these function more as annotation events than a system to extract information contained within full-text articles.3 Artificial intelligence (AI) tools for information integration have sought to overcome these obstacles while simultaneously decreasing the time input required from the researcher. Many of the currently existing AI models are limited to generating detailed groupings of articles based on their contents or extracting and comparing information only within narrow categories.4 These systems have yet to reach the point of providing users with thoroughly researched, discrete answers to their questions.
An online information management system (Refbin.com) was used to manually extract and integrate newly reported data from 1000 COVID-19 articles.5 As reported in our recent publication,5 extracted information was described using a minimum of four types of note fields (topic, population, description of the type of measurement and the actual reported measurement). Extracted results in the same topic were merged so that parent topic note fields were shared. The full text of each article was read and individual observations, such as the incidence rate of COVID-19 infection in college students, were manually entered into the database. That piece of information was grouped with similar observations from other publications. Rather than organising and filing information based on the publication, this new COVID-19 publication database was organised into logical groups of data such as mental health issues related to lockdown or observations on maternal to fetal transmission of COVID-19. A user of this database can readily see specific sets of information and navigate rapidly to increasing levels of detail. In this database, the user does not need to necessarily know what they are looking for and perform a search. The user navigates through topics covering all of the data to quickly find the information they need.
The aim of this pilot trial was to determine whether this new type of database would provide an operational improvement over conventional methods to more rapidly and more accurately find evidence to support statements about COVID-19. A sample of students from the University of Vermont was randomly assigned to use the COVID-19 publication database or their usual preferred search methods to research eight prompts about COVID-19. If assigned to use their preferred research methods, students were allowed to use any means they knew of to find and read primary research articles. We report here the results showing an improved outcome using the new system.
Methods
Study design
Eighteen participants were recruited from biomedically related courses and student organisations at the University of Vermont to participate in this randomised pilot trial. Prior to participating in the trial, the students completed a participant information survey including questions about their major, level of education, professional goals, research experience, usual speed of task completion and comfort with technology. The final sample included 17 students.
The participants were stratified based on self-rated questions about their previous research experience and usual task completion time requirements. Once stratified, the participants were randomly assigned to use either the new COVID-19 publication database (group A) or their preferred research methods (group B).
The trial was conducted over Microsoft Teams. Prior to taking the test, all participants received a 10 min step-by-step lesson on how to use the COVID-19 publication database prior to being assigned to group A or group B. The participants were informed that only evidence from primary literature would be counted as correct and that only 4 min were allowed per question. The tasks included finding specific pieces of information and were presented in survey form.
The relevance and accuracy of the evidence found for each prompt were individually graded by two members of our research team and then reviewed. Using parameters of specificity established during prompt development, each answer was graded in a binary of correct or incorrect. A correct answer submitted after 4 min (240 s) had passed was marked as incorrect. The time participants needed to answer each prompt was recorded by Qualtrics as the time elapsed between opening the question and clicking the submit button.
This pilot study qualified for an exemption from ethics review by the Institutional Review Board at the University of Vermont and the University of Vermont Medical Center. According to the definition of activities constituting research at these institutions, this pilot trial met the criteria for operational improvement activities and was, therefore, exempt from review.
Query prompt development
The prompts used in this investigation were written using a question stem stating a fact or observation about COVID-19, followed by a request for supporting evidence that the participant had to find using their assigned research method. At the time of this study, the COVID-19 database contained information on 1000 COVID-19 articles. Prompts were written by the study team that confirmed each prompt was answerable using both the COVID-19 database and Google (table 1). A preliminary investigation and refinement of the prompts were conducted with four students. Participants accessed the prompts through a Qualtrics survey, which randomly assigned them 8 of 18 total prompts.
The complete set of prompts administered at random to participants
Analysis of prompt and language difficulty was conducted using Microsoft Word’s readability tool. The Flesch-Kincaid Grade Level test yielded a score of 13.4, meaning that the language used in these prompts was best suited for those with some college education.
Statistical analysis
Statistical analyses were conducted using SAS Version 9.4 and SYSTAT Version 11 software. Contingency tables were created using the number of correctly answered prompts and the variables: research method (COVID-19 Database or other methods), day of study participation,1–17 academic background (major 1=biochemistry/biology; 2=dietetics, nutrition and food science (DNFS)), level of education (1=undergraduate; 2=graduate), previous research experience (1=uncomfortable; 2=neutral; 3=comfortable) and gender (0=male; 1=female).
A Cox proportional hazards’ model was used to analyse these data in a time-to-correct answer context. The Cox model and survival analyses in general are used widely throughout medical literature but have had limited use in the computer science literature.6–10 The event of interest in this study is a correctly answered question, enabling us to simultaneously evaluate completion time and accuracy. We examined the effect of several covariates on the time until a participant answered a prompt correctly or until their response was censored for being incorrect or over time.11 A sandwich estimator was used in conjunction with the Cox proportional hazards’ model to account for the clustering of responses by each participant.12 Kaplan-Meier plots were created to visualise the effect of the variables previously mentioned on the rate at which prompts were answered correctly and how many were answered correctly. The Kaplan-Meier estimator was selected due to its ability to handle right-censored data which took the form of wrong or incomplete answers in this pilot study.13 A Cox proportional hazard model for the search method as well as bivariate models for demographic factors were examined.
Results
Demographics and study groups
A total of 136 responses were collected, divided randomly, and nearly equally among 18 prompts. 72 responses were gathered from group A and 64 of these responses came from participants in group B (this discrepancy is due to incomplete data from the 18th participant) (table 2). One hundred and twenty of the total 136 responses were submitted by female participants reflecting the majority-female classes from which these students were recruited (online supplemental table 1). The study participants were stratified according to major and previous research experience and then randomly assigned to either group. This resulted in an equal number of the responses from group A (24) and group B (24) by students who identified as biology or biochemistry majors (online supplemental table 2). A similarly even distribution among the research methods was attained with students studying DNFS (group B=40, group A=48) (online supplemental table 2). The majority of the responses (104/136) were completed by participants who considered themselves neither uncomfortable nor comfortable in working with biomedical literature (online supplemental table 3). This trial spanned 17 days, from April 26 to May 12, 2021, with a relatively even distribution in the date of study completion among the research method groups. Pearson Chi-square tests showed no association between any of the previously mentioned demographic factors and the research method groups to which the participants were assigned.
Supplemental material
Number of responses by research method group
No significant associations were found using Pearson Chi-square when considering the day of participation, major and previous research experience in relation to the total number of correct responses across both research method groups. Within group A, biochemistry and biology majors answered 62.5% of their prompts correctly and DNFS students answered 45.8% correctly (p=0.18) (table 3). When looking at these same responses through the lens of previous research experience, it was found that group A students who rated themselves in the highest available category for comfort reading primary literature had a correct response rate of 75%, while the eight students who rated themselves in the middle category had a 48.4% accuracy rate (p=0.15) (table 4). Among the correct and incorrect responses obtained by group B, none of the evaluated demographic factors approached significance.
Percentage of correct responses from group A participants by major
Percentage of correct responses from group A participants by comfort using and reading research literature (research experience)
Kaplan-Meier plots: combined and by research method
Kaplan-Meier plots were used to simultaneously examine the accuracy of each response and the time required to obtain it. Using the survival analysis terminology frequently found in biomedical literature, exact failures or deaths correspond to prompts answered correctly and survival time represents the number of seconds required for the correct response. Right censored responses are those that were either obtained in more than 240 s or were incorrect. The survivor function in the Kaplan-Meier plots below, therefore, demonstrates the proportion of responses that were correct (died) within the time spent on each response.
The Kaplan-Meier plot in figure 1 shows the prompts answered by group A were more frequently answered correctly and more rapidly than group B. A log-rank test yielded a p value <0.001. The mean survival times for prompts at risk of failing (being answered correctly) were 226.8 s and 365.5 s for group A and group B, respectively. The overlap in the survival curves in figure 1B indicates a degree of homogeneity among the group A participants (p=0.259). Figure 1c contains the survival plot of group B. The overlap of curves here also indicates a degree of homogeneity among group B (p=0.466). Due to there only being 12 correct responses out of 64 at risk in group B, both the similarity of the survival curves and the mean survival time could be slightly distorted. This was not an issue in group A where there was a total of 37 correct responses out of 72 prompts answered.

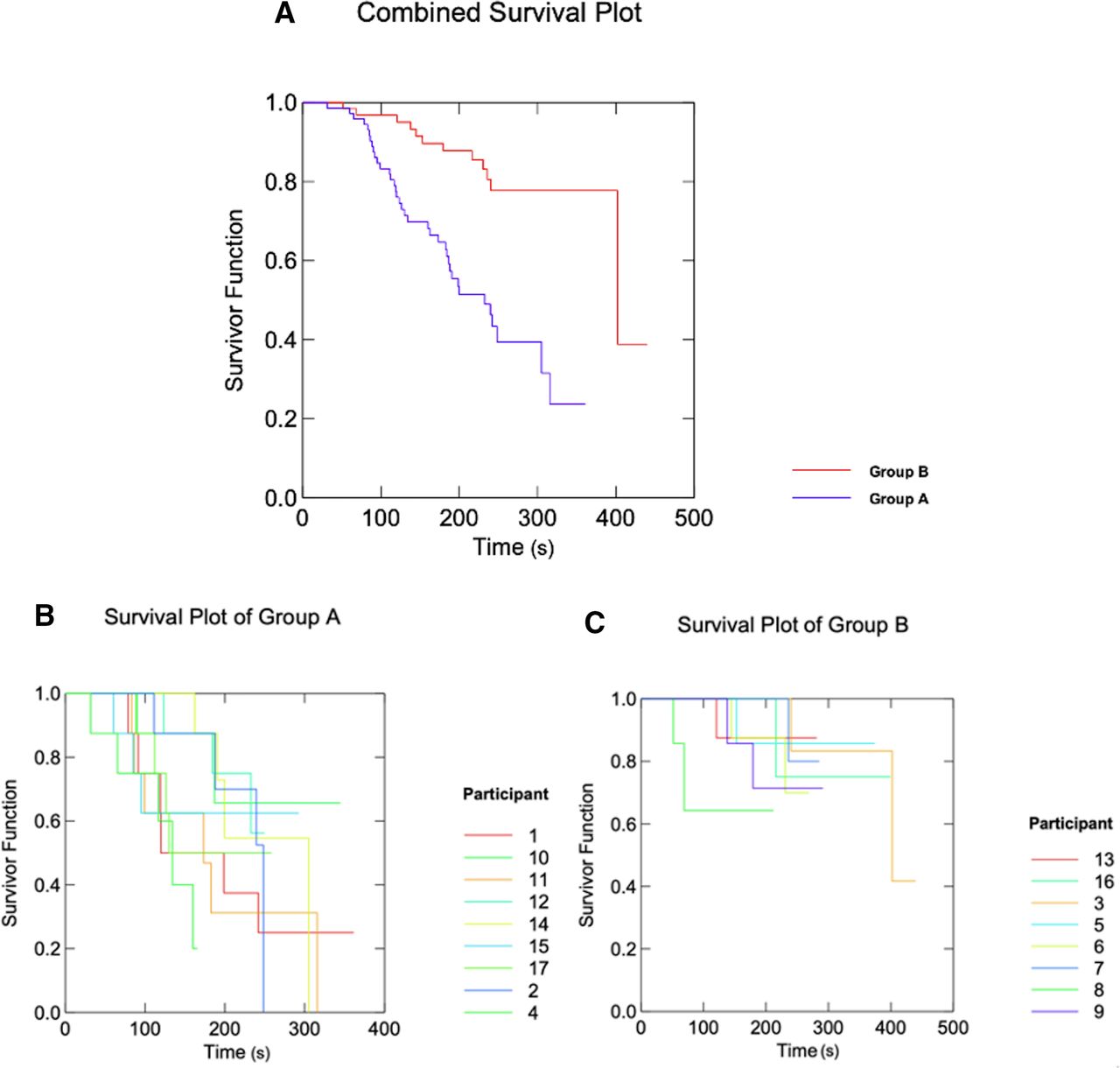{kind=link}
Kaplan-Meier plots showing the survivor function for group A compared with group B (A), as well as for the participants within group A (B) and group B (C) independently.
Cox proportional hazards’ models with Sandwich Estimator
A Cox proportional hazard model using a Sandwich Estimator was conducted as described by Lin and Wei to account for the clustering of responses by participant.12 The analysis of the research method resulted in a parameter estimate for group A of 1.388 (SE of 0.254, p<0.001). The HR of obtaining a correct response in the context of the method parameter was 4.01 (95% CI 2.433 to 6.579).
Bivariate Cox models of analyses for the research method and gender, day of study participation or major demonstrated a consistently more significant influence of the research method on response accuracy than the alternate variable. The bivariate model parameter estimate for women was 0.144 (SE of 0.168, p=0.39), for day of study participation −0.008 (SE of 0.014, p=0.579) and for major 0.392 (SE of 0.235, p=0.096). The bivariate hazard ratios were as follows: woman, 1.154 (95% CI 0.830 to 1.606); study day, 0.993 (95% CI 0.67 to 1.019); and major, 0.676 (95% CI 0.426 to 1.072). The level of research experience, in contrast to the previous parameters, resulted in a more significant parameter estimate of 0.542 (SE of 0.118, p<0.0001) and a HR of 1.719 (95% CI 1.363 to 2.167). A correlation matrix was used to show that despite the larger parameter estimate of previous research experience, research method and experience were independent (r=0.022).
Discussion
This randomised pilot trial was performed to determine whether a new information platform containing information from 1000 COVID-19 publications enabled faster and more accurate answers to prompts than conventional methods of accessing biomedical information. Kaplan-Meier plots and Cox Proportional Hazard Models confirmed that the new method of information integration (group A) enabled participants to answer prompts about COVID-19 more quickly and accurately.
Tests for respondent heterogeneity within groups A and B were negative. The paucity of correct answers collected by group B may in part be attributable to the difference between the volume of sources retrieved by a Google search compared with a search in the group A COVID-19 database. After completing the prompts, many of the members in group B commented that 4 min was simply not enough time to find answers. This rush for time coupled with the many blank responses seen from this group could reflect the negative correlation between time per question and user satisfaction described by Xu and Mease.14 The discrepancy in timed-out prompts and blank responses between the two groups could simply be the result of the pace at which research was completed using the two methods, but it could also provide insight into frustration among participants using traditional research methods. Allowing each participant to be exposed to the full range of questions was part of the design for comparability among students. A limit of 4 min allowed each participant to be exposed to the full range of questions. This was a study design tradeoff between comparable exposure within a specific time frame versus unbounded time to complete the search and having a non-comparable opportunity to answer all specific questions. The choices of the questions were also designed to be not that sophisticated as to make questions too difficult to be able to abstract from each of the differing approaches. There are differences when conducting real-world research and this pilot evaluation study of the interface and database.
A significant difference was seen between the number of correct answers gathered by group A and group B. This observation contrasts with other examples from the literature.15 16 For example, when using a question answering system compared with a document retrieval system, Smucker et al found that participants answered questions correctly at similar rates.15 The question answering system described in the Smucker study resembles the new COVID-19 database in that they both aim to present condensed, succinct information independently of its source articles. Therefore, we suspect that the marked improvement in answer accuracy observed in our study may be related to the format in which information is presented. The parent–child organisation structure in the new database system may enable users to more easily adjust the information they are viewing without repeatedly editing their query.
A set of bivariate Cox proportional hazard models showed that among the demographic factors considered in this pilot study previous research experience was the only one to confer an advantage in study performance. A correlation matrix, however, indicated that the pre-stratification of participants had evenly distributed their degree of prior research experience between the two groups. When examining responses from just group A, major (biology and biochemistry v. dietetics, nutrition and food sciences) and previous research experience did approach significance. This indicates that familiarity with research literature and biomedical language is potentially advantageous in using the database, but ultimately not to a significant extent. In general, studies evaluating information retrieval systems with user-oriented methods have had similar trouble identifying significant extraneous influences on user performance. Whether collecting data on age, sex, computer experience, online search engine familiarity or career objectives these examples from the literature show no significant differences between the groups assigned to the different search methods nor accuracy rates.16–18
In this pilot randomised trial, statistically significant differences were observed between groups A and B. This emphasised the marked differences between the methods and warrant expansion of the trial to validate the results. In addition to increasing the sample size, it will be helpful to source queries from a separate set of participants, experts on the topics addressed by the database or search history data from commercial engines.14 16 19 It will also be useful to expand the diversity of participants' education status. Determining the range of students and users that could benefit from this new platform for information will help guide integration into educational systems. A limitation of the Refbin system is that, unlike Google Scholar and PubMed, methods to continuously update the database are not yet implemented.
Conclusion
We demonstrated that a new method of extracting information from published biomedical literature allows users to more quickly and more accurately answer questions related to COVID-19. Topics such as COVID-19 present so much data that a next-generation system is required to more rapidly allow users to answer questions related to the published data. This pilot study with 1000 COVID-19 manuscripts points to a possible solution to speed up research.
Data availability statement
Data sharing not applicable as no datasets generated and/or analysed for this study.
Ethics statements
Patient consent for publication
Ethics approval
This study involves human participants but all methods were carried out in accordance with relevant guidelines and regulations as defined by the University of Vermont Institutional Review Boards (IRBs) serving the University of Vermont and the University of Vermont Medical Center. The present pilot study was classified as operational improvement activities by the IRBs. According to the definition of activities constituting research at these institutions, the methods of this pilot did not qualify as research and were exempt from ethics review. The IRBs thereby approved all methods carried out in this pilot study to proceed without further review. Informed consent was obtained from all individual participants included in this pilot study, exempted this study. Participants gave informed consent to participate in the study before taking part.
Supplementary materials
Supplementary Data
This web only file has been produced by the BMJ Publishing Group from an electronic file supplied by the author(s) and has not been edited for content.
Footnotes
Contributors CTL is guarantor.
Funding The authors have not declared a specific grant for this research from any funding agency in the public, commercial or not-for-profit sectors.
Competing interests David Krag has a significant financial interest in Plomics Inc, the developer of RefBin.com. The investigator disclosed his personal financial interest to the IRB of the University of Vermont. The IRB at the University of Vermont and the University of Vermont Medical Center determined that this pilot study qualified for an exemption from ethics review. Any potential conflicts of interest were managed. All other authors declare that they have no conflicts of interest.
Provenance and peer review Not commissioned; externally peer reviewed.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.